Teoría

Escrito por
11 minutos de lectura
CNN Layers and Feature Visualization
Convolutional Neural Networks (CNN)
Este tipo de red neuronal se encarga de encontrar y representar patrones en un espacio en 3D y es la más potente a la hora de realizar tareas de procesamiento de imágenes.
Una peculiaridad de esta red es que, en vez de enfocarse en los valores de los píxeles individualmente, se enfoca en un grupo de píxeles de un área de la imagen gracias a las convoluciones (Sección 2) que realiza y aprende de ella sus patrones característicos.
A medida que entrenamos la red, esta va actualizando las ponderaciones que definen cómo se filtra la imagen utilizando el backpropagation
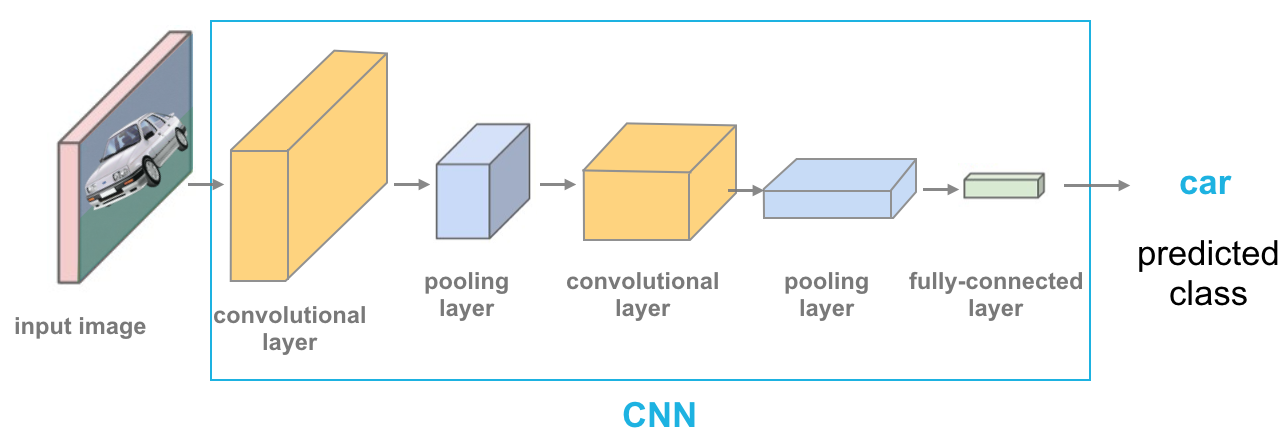
Imagen de @cezannec (GitHub)
Cada capa es representada como un paralelepípedo de distinto color.
1ª Capa: Convolutional layer:
- Toma una imagen como input.
- Es una capa ya que está formada por una serie de convoluciones, en las cuales extrae una determinada característica. Por ejemplo, un filtro high-pass (Sección 2) de una convolución se encargaría de detectar los bordes del objeto.
- El output de una convolutional layer es un set de feature maps (o activation maps) que son las versiones filtradas de la imagen original.
Tras la convolutional layer se ejecuta la función de activación ReLu que hace un input “x” 0 cuando este es negativo o igual a 0 (x <= 0) y 1 cuando es mayor a 0 (x > 0). El trabajo de las funciones de activación es hacer más eficiente el backpropagation y que así sea más efectivo entrenar la red neuronal.
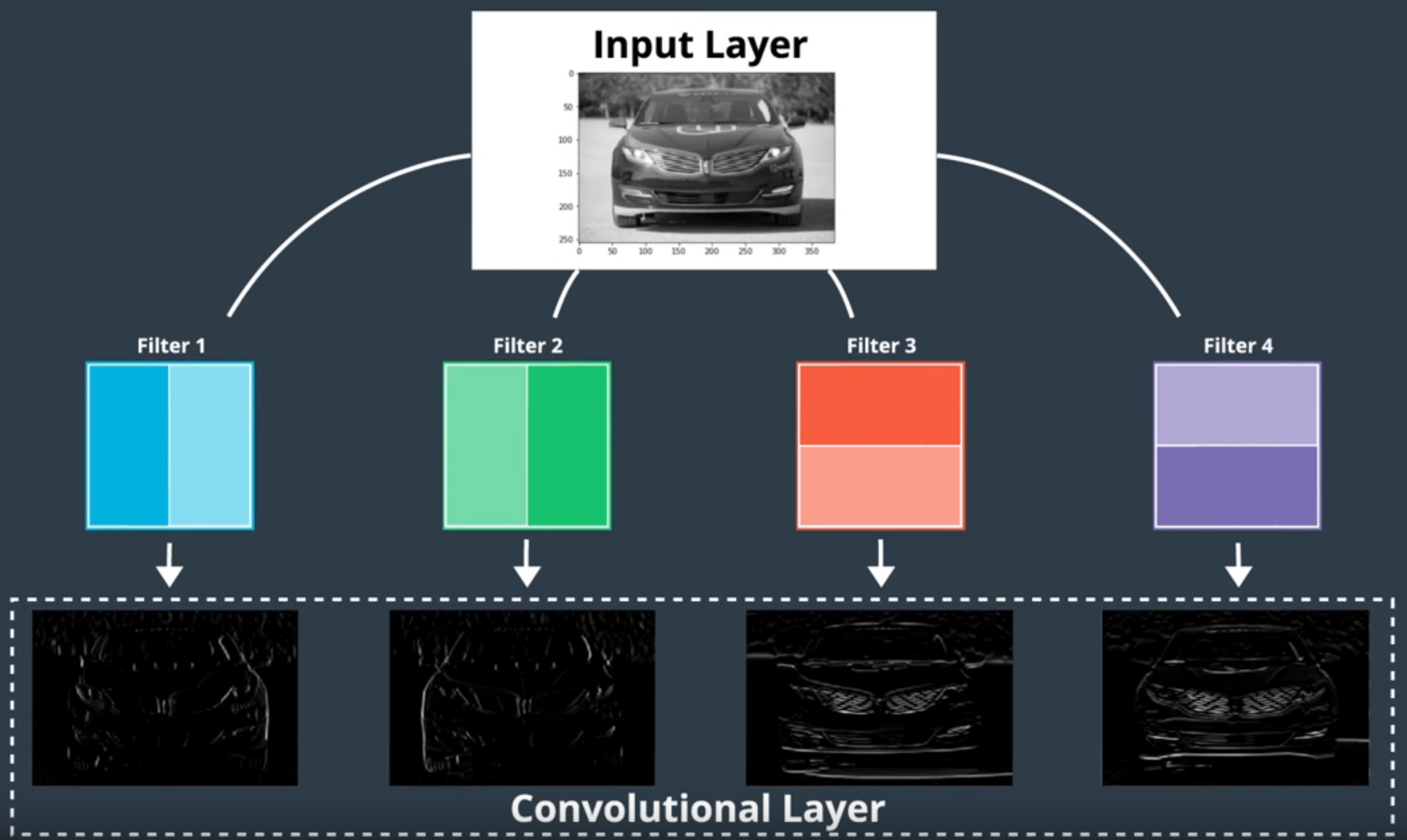
4 filtros o convoluciones y su respectivo feature map - Imagen de Udacity
Lo más interesante de esto es que podemos volver a aplicar una convolutional layer sobre los feature maps que ya habíamos obtenido, buscando así patrones sobre los patrones encontrados de la capa anterior.
2ª Capa: Pooling layer:
Encargada de reducir el tamaño de la matriz de píxeles de la imagen de entrada para así acelerar el proceso.
Esto es muy útil en Deep CNN ya que al aumentar los parámetros, también aumentan las posibilidades de sufrir overfitting.
-
Maxpooling Layers: Seleccionan un área de una imagen (la matriz 2x2 de la imagen inferior) y devuelven el valor más alto. Esto, siguiendo el ejemplo anterior, lo haría con las otras 3 matrices 2x2 dando resultado a una matriz:
np.array([[4, 8], [6, 9]])

Maxpooling layer - Imagen de machinecurve.com
- Global Average Pooling Layer: Suma todos los valores de la matriz y divide la suma entre el número de elementos de la matriz. Reduciendo toda la matriz a un único elemento. 69 / 16 = 4.3125.
Penúltima capa: Fully-connected layer:
Su misión es conectar el input que recibe con la forma del output que se necesita. Es decir, convierte los feature maps (o cualquier matriz) en un vector con dimensión 1xC (siendo C el número de clases).
Última capa: Softmax:
Toma un vector y devuelve otro del mismo tamaño pero con valores en un rango de 0 a 1. Y, al sumar el valor de los vectores, el resultado es 1. Esto es lógico, ya que cada elemento del vector representa una cierta probabilidad y al sumar todas las probabilidades el resultado debe ser 1 (El output se suele llamar class scores).
Por lo tanto, esta función es vista especialmente en los modelos de clasificación, ya que tienen que transformar un feature vector en una distribución de probabilidad.
Otras capas:
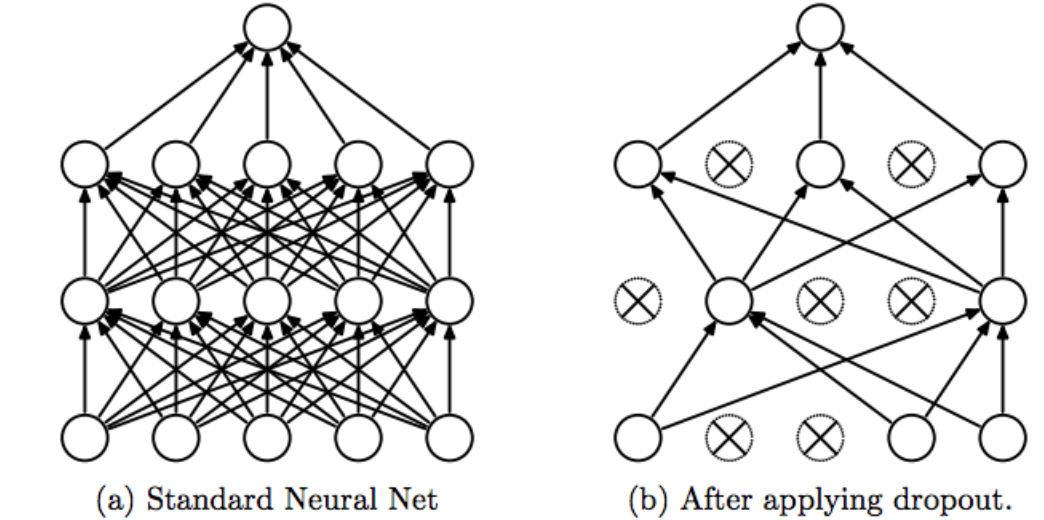
Dropout layer:
Su función es evitar el overfitting. Para ello apaga con cierta probabilidad los nodos o neuronas (las cuales forman parte de las capas de nuestra red) de forma aleatoria.
Por lo tanto, se asegura de que todos los nodos obtengan las mismas oportunidades para intentar clasificar las imágenes durante el entrenamiento, lo que evita que los nodos con mayores ponderaciones dominen el proceso , llevando así al overfitting. Con lo que si un nodo comete un error, este no dictaminará el comportamiento de la red.
Para reducir el overfitting también podemos utilizar el Batch normalization por ejemplo.
Arquitectura de una CNN en Pytorch:
import torch.nn as nn
import torch.nn.fuctional as F
class Net(nn.Module):
def __init__(self, n_classes):
super(Net, self).__init__()
# 1 canal de la imagen de input (en escala de grises)
# 32 feature maps como output
# 5x5 convolutional kernel
self.conv1 == nn.Conv2d(1, 32, 5)
# Maxpooling layer
# Kernel de tamaño 2 y paso de 2
self.pool = nn.MaxPool2d(2, 2)
# Fully-connected layer
# 32*4 es el tamaño del input después de la pooling layer
self.fcl = nn.Linear(32*4, n_classes)
# Definir la feedforward propagation
def forward(self, x):
# Conv/ReLu + pool layers
x = self.pool(F.relu(self.convl(x)))
# Preparar para convertir los feature maps en feature vectors
x = x.view(x.size(0), -1)
# Linear layer
x = F.relu(self.fcl(x))
return x
# Instanciar e imprimir la red
n_classes = 20 # Número de clases
net = Net(n_classes)
print(net)
Ver el documento CNN Básica con Pytorch para verlo implementado.
Optimizadores
Son utilizados para reducir el error de nuestra red cuando la entrenamos.
Dos muy utilizados para clasificación son:
- Stochastic Gradient Descent (SGD).
- Adam.
Momentum: Es un parámetro utilizado en los optimizadores que tiene una gran implicación en el gradient descent, permitiendo moverse de un mínimo local para así encontrar un máximo global.
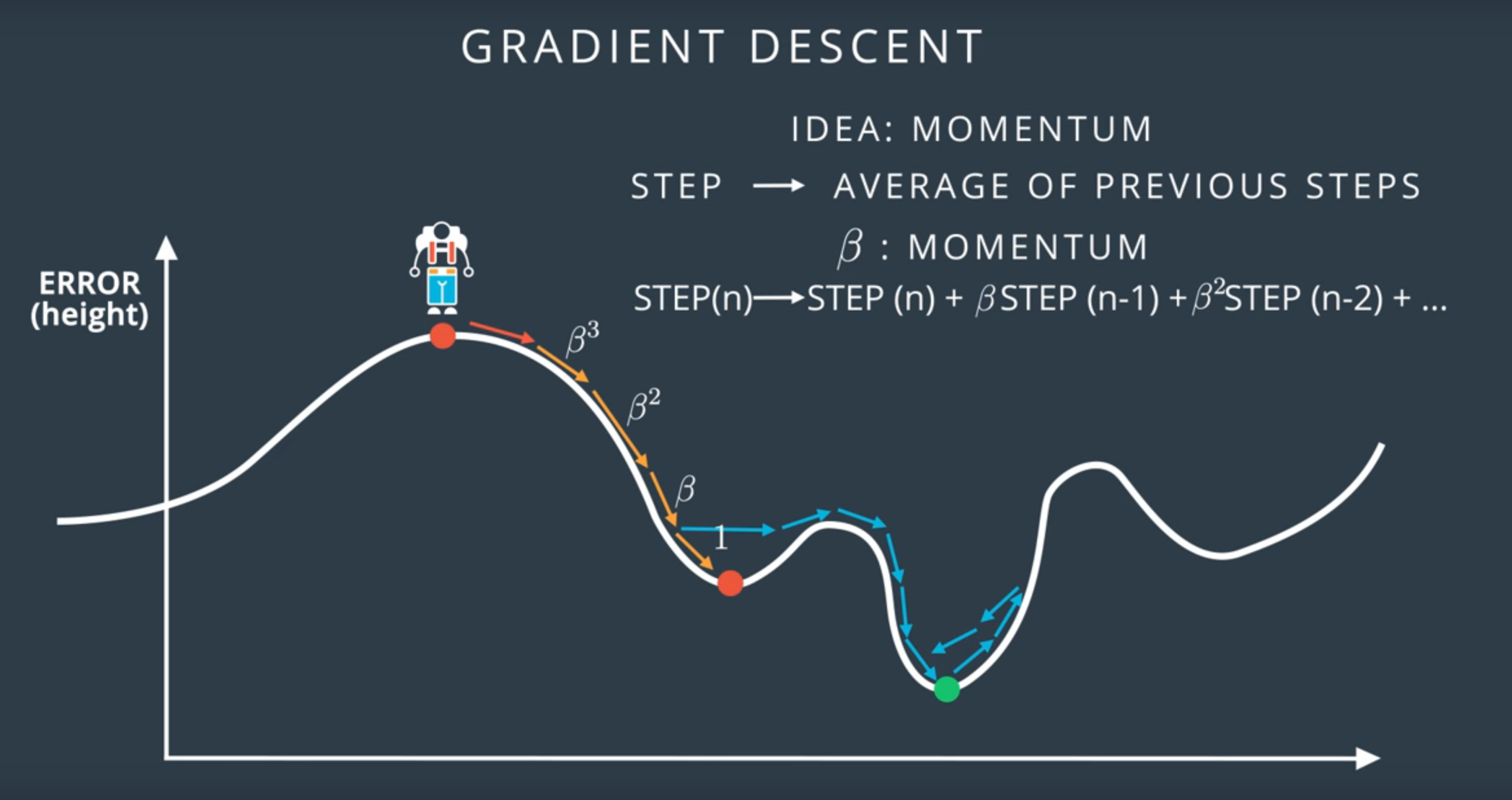
Momentum en el gradient descent - Imagen de Udacity
Para ver todos estos conceptos aplicados a un modelo de clasificación de ropa ver el archivo “Clasificación de moda con Pytorch”.
Feature Visualization
Consiste en comprobar qué tipos de features ha aprendido la red a reconocer.
Ejemplo: Si tenemos una CNN que clasifica entre perros y lobos pero la mayoría de las imágenes de lobos son en la nieve, cuando el algoritmo tenga que clasificar una imagen de un perro en la nieve lo hará como un lobo ya que el algoritmo había dado importancia a la nieve en las imágenes del lobo al no haberle incluido más en diferentes lugares.
Para visualizar los feature vectors de la capa final deberemos reducir la dimensionalidad del último feature vector para que lo podamos visualizar en un espacio 2D o 3D. Para ello podemos utilizar las siguientes técnicas:
-
Principal Component Analysis(PCA): Comprime el vector a 2D creando dos variables (x, y) como funciones de estos features.
-
t- SNE: Separa los datos de forma que se creen clusters separados con información similar.

Distribución de MNIST organizada en clusters por t-SNE - Imagen de Udacity
-
Occlusion Experiments: Tapa determinadas partes de la imagen y ve cómo responde la red dando como resultado un mapa de calor que muestra la clase predicha de una imagen como una función de qué parte de una imagen fue ocultada (occluded).
Procedimiento:
- Realiza una máscara de parte de una imagen antes de alimentarla a la CNN ya entrenada.
- Dibuja un mapa de calor de las class scores (los resultados probabilísticos de la CNN) para cada máscara de imagen.
- Deslizar la máscara a un punto diferente de la imagen y repetir los pasos 1 y 2.
-
Saliency Maps: Un saliency map busca qué píxeles son los más importantes a la hora de clasificar una imagen. La forma en la que lo hace es computando el gradiente de las class scores con respecto a los píxeles de la imagen.
Un proceso que se realiza para computar los gradientes es el guided backpropagation. Su función es ver qué le ocurre al output de la red si cambiamos ligeramente cada píxel de la imagen de entrada. Si el output presenta un cambio drástico entonces el píxel que experimentó el cambio es importante para esa capa en particulas.

Saliency map - Imagen de Udacity
¿Cómo funciona la transferencia de estilos?
![]()
Transferencia de estilos en una imagen de un gatos y olas - Imagen de Udacity
Su función es separar el contenido de una imagen de sus estilos. Para ello sigue el siguiente procedimiento:
- Aislar el contenido: A medida que la CNN se va haciendo más profunda, la imagen de entrada se va transformando en feature maps que cada vez le dan más importancia al contenido de la imagen que a cualquier detalle sobre la textura o el color de la imagen (los estilos).
- Aislar los estilos: Se utiliza un feature space el cual busca las correlaciones entre los feature maps en cada capa de la red. Estas correlaciones nos dan una idea de la información de las texturas y el color.
- Combinación de estilos y contenido para crear una nueva imagen: El algoritmo Neural Style Transfer (NST) toma dos imágenes con diferentes estilos y contenido. Entonces, para crear una nueva imagen simplemente toma el contenido de una imagen y aplica los estilos de la otra.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}