Teoría

Escrito por
7 minutos de lectura
RNN’s (Recurrent Neural Networks)
Son un tipo de redes neuronales que nos permiten no sólo considerar el único input de entrada, sino inputs con los que había trabajado en el pasado. A estos se les conoce como dependencias temporales. Por ello, podemos decir que tienen “memoria”. Esto será que será crítico en el análisis de datos secuenciales como el análisis de texto o e aplicaciones en tiempo real.
Las RNN se llaman así porque llevan a cabo la misma tarea para cada elemento en la secuencia del input, es decir, de forma recurrente.
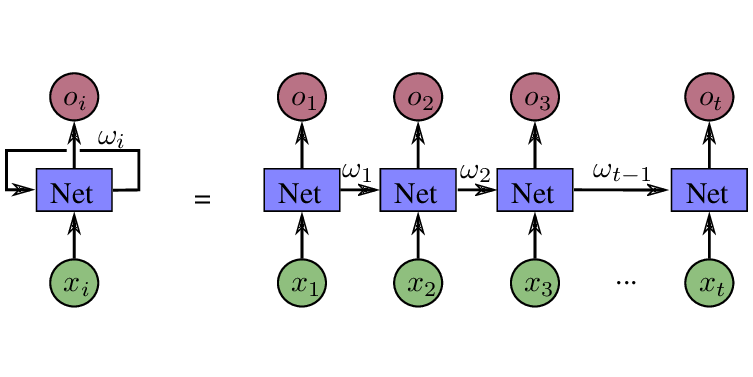
Representación gráfica de una RNN
Ejemplos
Si, por ejemplo, nos imaginamos el frame de un vídeo en el que un gato está saltando igual para nosotros podría ser relativamente sencillo distinguir la acción que está realizando. En cambio, para una máquina no lo sería. Por lo que esta necesitaría visualizar los frames anteriores del vídeo y, acordándose de los frames anteriores, poder clasificar la acción del gato. Este constituye un papel que pueden jugar las RNN’s en el computer vision.

Imagen de un gato saltando
También podríamos imaginarnos una pelota como la situada en la imagen inferior. ¿Serías capaz de predecir hacia donde se dirige? Por las leyes de la física podríamos deducir que hacia abajo, sin embargo puede que esté en movimiento por una patada y se dirija hacia la derecha, hacia arriba, hacia la izquierda, etc. Por lo tanto, deberíamos ver en qué posición se encontraba anteriormente para poder sacar conclusiones. Así es como funcionan las RNN, manteniendo dependencias temporales para así poder extraer conclusiones.

Bola sobre un fondo azul
Si quieres ver cómo una RNN puede continuar tus dibujos, échale un ojo al siguiente link: Aplicación web de dibujo con una RNN
Por otra parte, si quieres leer cómo clasificar vídeos y generar subtítulos o una leyenda para ellos, visita el siguiente enlace: Paper sobre el papel de las RNN en el entendimiento de vídeos
Historia
Tras la primera ola de redes neuronales artificiales a mediados de los años 80, uno de los problemas de estas surgía al no poder capturar dependencias temporales.
El primer intento para tratar de añadir memoria a las redes fue la Time Delay Neural Network(TDNN) en 1989. En ellas, los inputs de anteriores pasos eran introducidos en la red. Sin embargo, estaban limitadas por el límite de tiempo escogido.
A las siguientes, propuestas en 1990, se les dió el nombre de RNN’s simples (también conocidas como la red de Jorda y la red de Elman).
Pero a principios de los años 90 se reconoció que estas redes sufrían del llamado vanishing gradient problem, el cual alegaba que las contribuciones de información iban decayendo con respecto al tiempo (En series geométricas). Así que obtener relaciones procedientes a más de 10 pasos era prácticamete imposible.
A mediados de 1990 surgieron las Long Short-Term Memory(LSTM). La idea de estas es que algunas señales, llamadas call state variables, pueden mantenerse fijadas utilizando computertas y ser o no reintroducidas en un tiempo futuro. De esta forma se podían representar intervalos de tiempo arbitrarios y capturar dependencias temporales.
Más adelante, algunas variaciones en las LSTM’s como las Gated Recurrent Networks refinarán los conceptos hablados anteriormente.
Aplicaciones
- Reconocimiento de voz: Secuencias de ejemplos de datos extraídos de una señal de audio son continuamente representados como texto. Ej. Google Assistant.
- Time series prediction:
- Patrones de tráfico: Predicción de patrones de tráfico en rutas específicas para ayudar al conductor a optimizar sus trayectos de conducción. Ej. Waze.
- Selección de películas: Mostrar una recomendación de la película que ver a continuación según nuestros gustos. Ej. Netflix.
- Movimientos y condiciones de la bolsa y el mercado: Predecir los movimientos que se realizarán en la bolsa en base a patrones históricos u otros movimientos del mercado que se harán a lo largo del tiempo.
- Añadir automáticamente silencios a las películas.
- …
- Procesado de lenguaje natural (NLP):
- Machine translation. Ej. Google translate.
- Respuesta a preguntas. Ej. Google Analytics para hacer preguntas sobre nuestra app.
- Chatbots. Ej. Chatbots de slack, discord, DotA 2 bot de Open AI, …
- …
- Reconocimiento de gestos. Algunas compañías que lo están aplicando a sus productos son Intel, Qualcomm, EyeSight, …
Diferencia entre la tradicional Feed Forward Neural Network (FNN) y la RNN
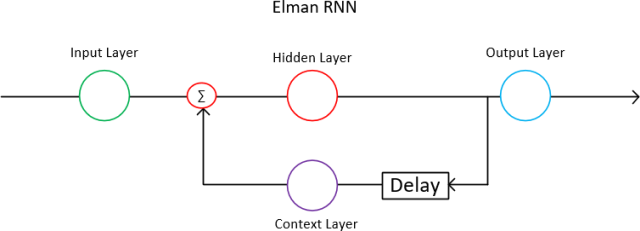
Elman Network simplificada - Imagen de Codeproject
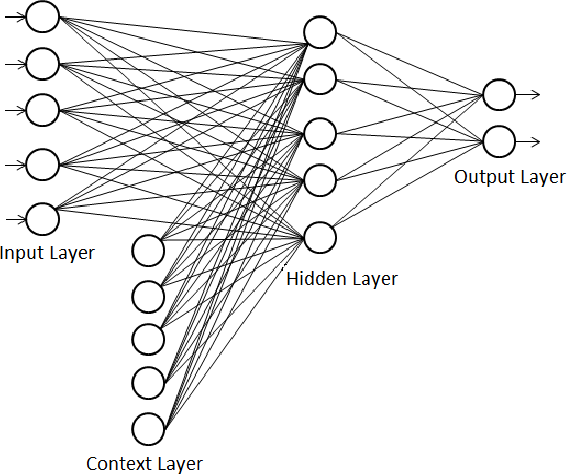
Elman Network diagrama completo - Imagen de Codeproject
Las dos principales diferencias son:
- Secuencias como input en la fase de entrenamiento. Vemos en la imagen superior como a la capa de inputs se le añade una capa de contexto que posee la memoria de otros entrenamientos.
- Los elementos de memoria. La memoria son los outputs de las neuronas que se encuentra en las capas ocultas (en este caso solo en una).
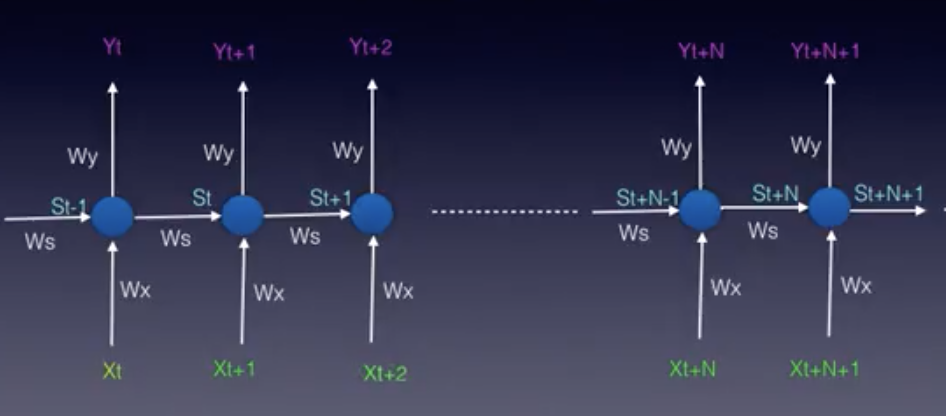
x: vector de input | y: vector de output | s: vector de estado
Elman Network representación matemática - Imagen de Udacity
phi: función de activación | W: ponderaciones | t: tiempo
Ecuación de la capa de estado
Ecuación del output de una RNN
Backpropagation Through Time (BPTT)
Al igual que en las FNN, se realiza el backpropagation. Sin embargo, debemos considerar los pasos a través del tiempo debido a que nuestro sistema ahora posee memoria. Por lo tanto, lo llamaremos backpropagation through time.
\[E_t = (d_t-y_t)^2\]E: Error del output | d = Output deseado
Función de coste

BPTT desde el estado 3 hasta el inicio, representación matemática haciendo uso de la chain rule - Imagen de Udacity
Si nos fijamos en la imagen superior, el primer sumando representa las ponderaciones del tercer estado. El segundo sumando las del segundo. Y el último las del primero.
Por lo que la ecuación general sería la siguiente:
\[\frac{\partial E_N}{\partial W_s} = \sum_{i=1}^{N}\frac{\partial E_N}{\partial y_N}*\frac{\partial y_N}{\partial s_i}*\frac{\partial s_i}{\partial W_s}\]Nótese que Ws designa las ponderaciones entre diferentes estados. Si queremos ajustar Wx (las ponderaciones entre los inputs y las neuronas) simplemente reemplazamos Ws por Wx.
A la hora de calcular el gradient descent lo haremos cada cierto número de pasos N mediante la siguiente ecuación.
\[\delta = \frac{1}{m}\sum_{k}^{m}E_{k}\]Esto reducirá la complejidad del modelo y también el ruido.
El problema de esta red neuronal es que, como comenté al inicio, únicamente nos será útil para un máximo de 10 estados. A partir comenzará a sufrir problemas como el vanishing gradient (el gradiente será tan pequeño que se aproximará a 0), además de su realentización.
\[\delta = \frac{\partial{y}}{\partial{W_{ij}}} \approx 0\] \[\frac{\partial{E_t}}{\partial{s_{t-N}}} \approx 0\]Vanishing gradient problem representado matemáticamente
Para solventar ese problema se utilizan las Log Short-Term Memory Cell(LSTM). Esto lo hace guardando cierta información tras una gran cantidad de pasos. Para saber más sobre la principal RNN utilizada en la actualidad, visita la siguiente sección.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}