Teoría

Escrito por
3 minutos de lectura
Long Short Term Memory networks (LSTM)
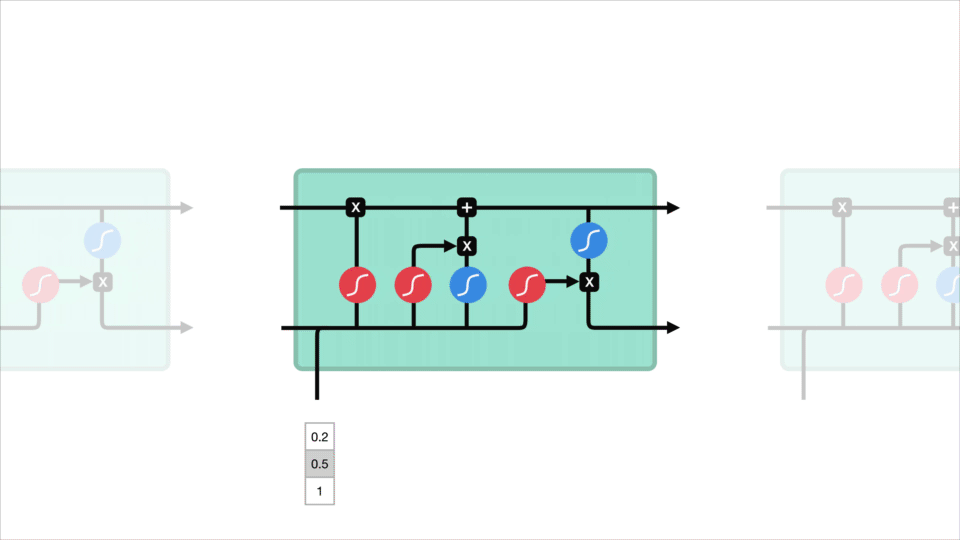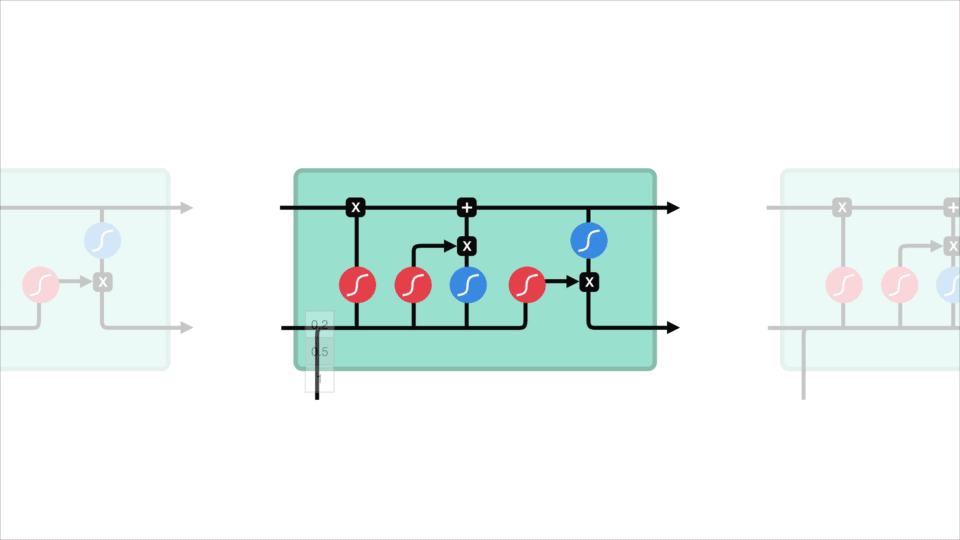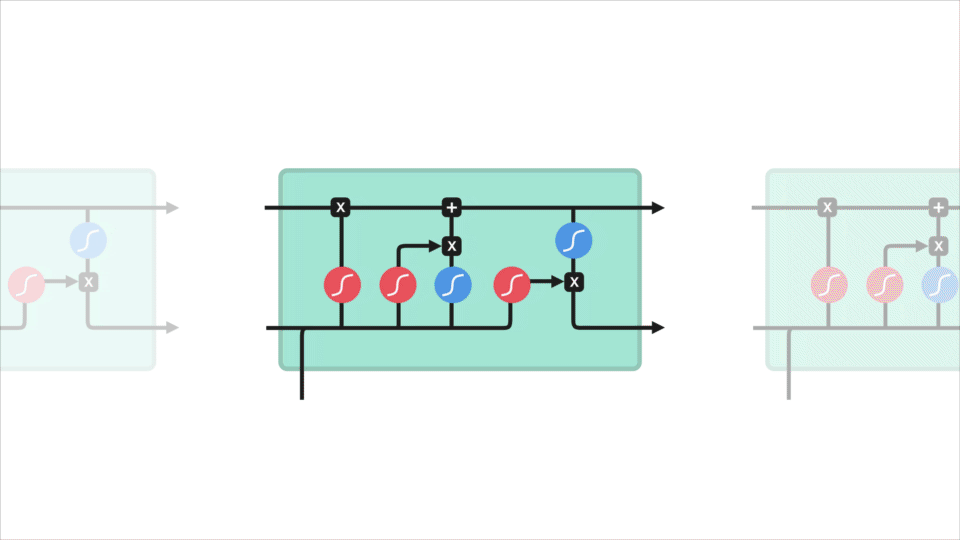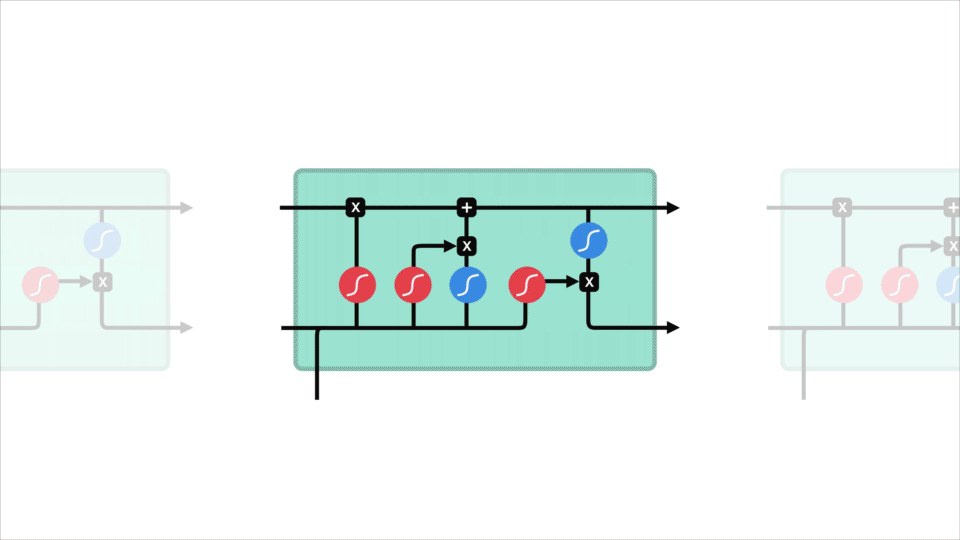
Representación de las neuronas de una LSTM - Imagen de Michael Nguyen
Como he hablado en secciones anteriores, las RNN’s poseían el vanishing gradient problem, recaptiulando, tras 10 estados de memoria el gradiente comenzaba a aproximarse a 0 poseyendo así una memoria a corto plazo. Si se le suministraba una secuencia lo suficientemente larga a una Simple RNN le costaría llevar la información hasta los últimos pasos. Para solucionar esto surgieron las Long Short Term Memory networks de las cuales hablaré en este artículo.
Muchas de las ilustraciones y GIF que voy a utilizar pertenecen al artículo “Una guía ilustrada de LSTM’s y GRU’s: Explicación paso a paso” - Michael Nguyen el cual recomiendo echar un ojo.
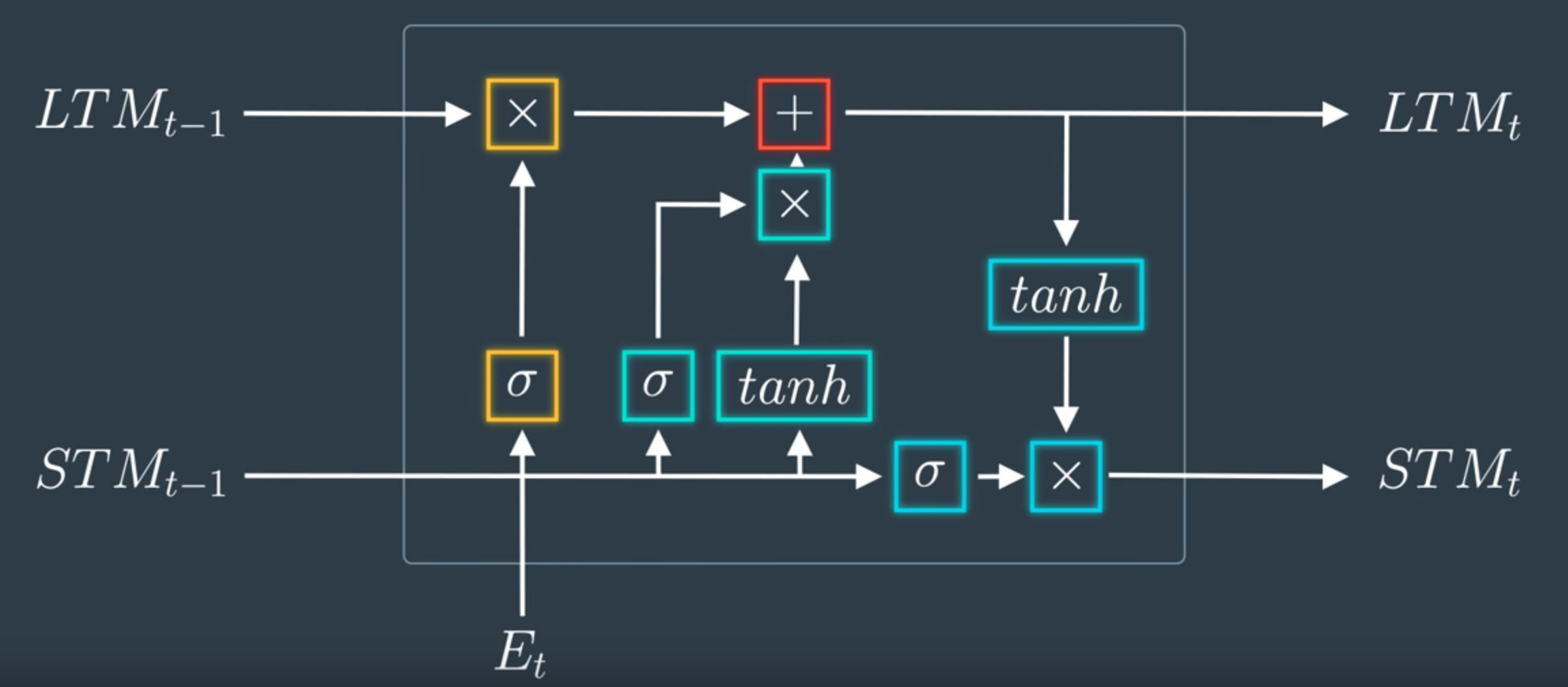
Neurona de una LSTM - Imagen de Udacity
El principal componente de una LSTM son sus neuronas y creo que para entender cómo funciona esta red lo mejor es comenzar entendiéndolas.
Memoria a corto y largo plazo (Long and Short memory)
Fijémonos en los inputs:
Et es el vector que recibe la neurona para computar.
LTMt-1 representa la memoria del bloque anterior, esta es la memoria a largo plazo. Y STMt-1, al contrario que el anterior, constituye el output del bloque anterior, es decir, la memoria a corto plazo.
Y respecto a los outputs:
STMt es el output de la neurona y, a su vez, representa la memoria a corto plazo que será alimentada al siguiente bloque. Por otro lugar, LTMt es la memoria a largo plazo del bloque ya computada para ser transferida también al siguiente bloque.
Para ver la implementación en código: Inputs y Outputs de una LSTM en código
Compuertas (Gates)
La forma en la que la neurona computa los inputs para dar lugar a los outputs es mediante una serie de computertas:
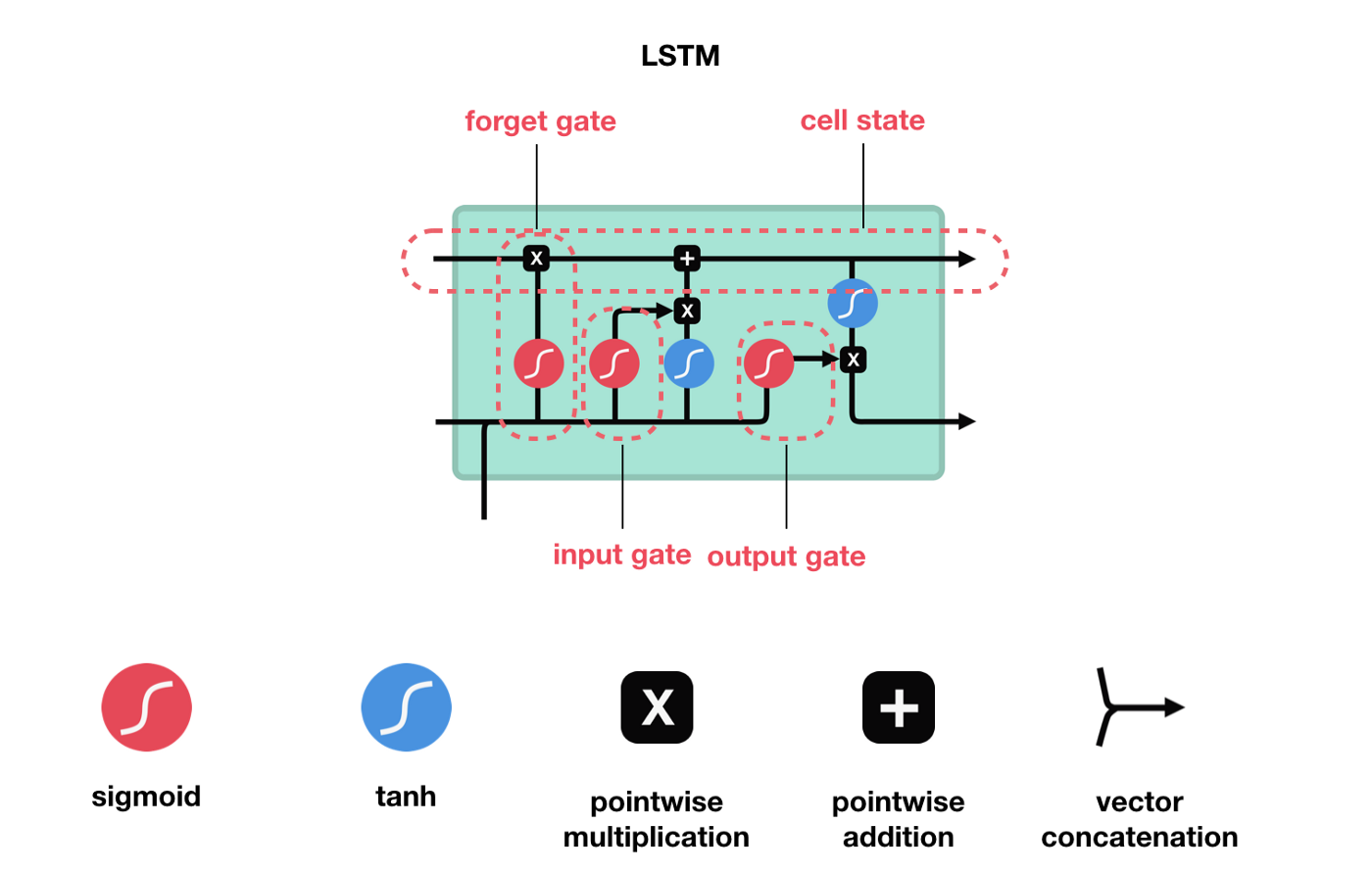
Compuertas de una LSTM - Imagen modificada de Michael
Input Gate (or Learn Gate)
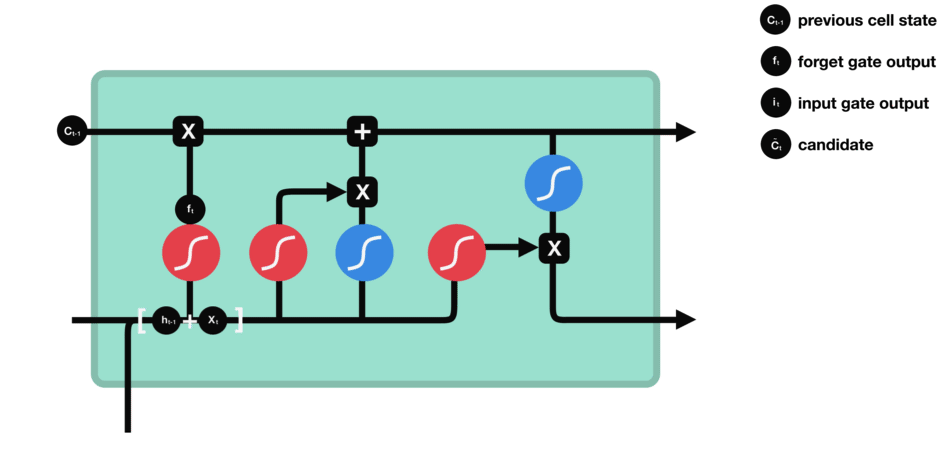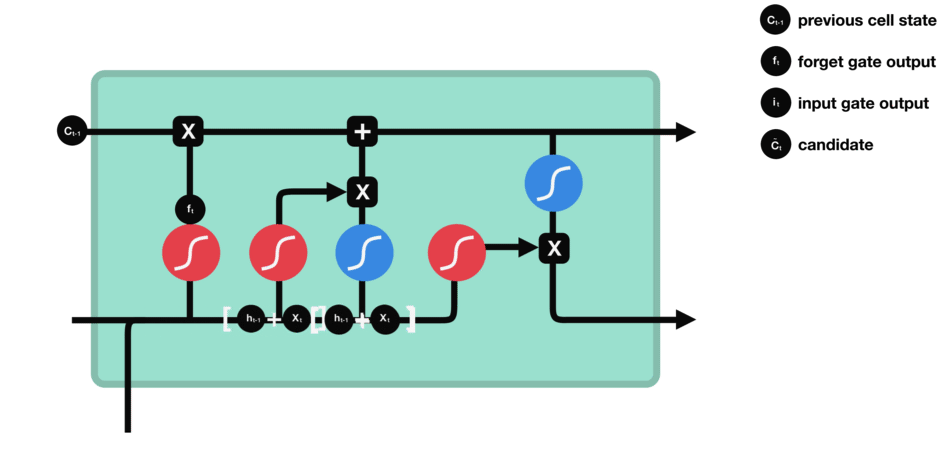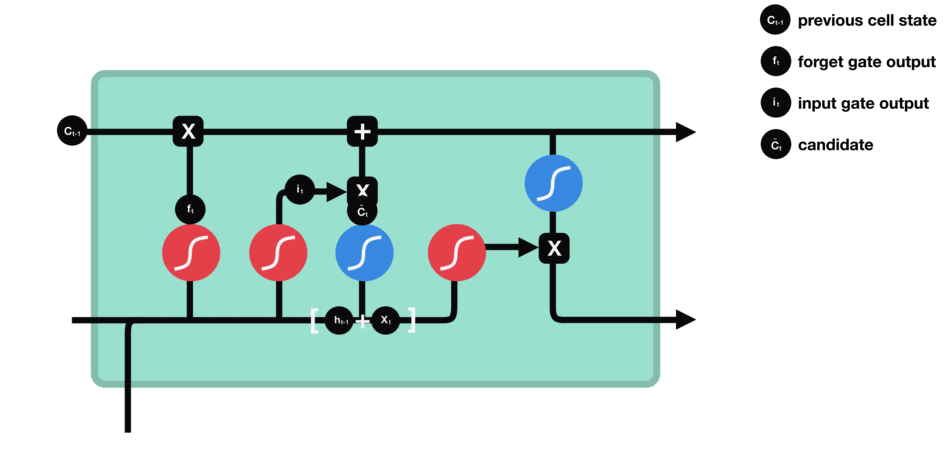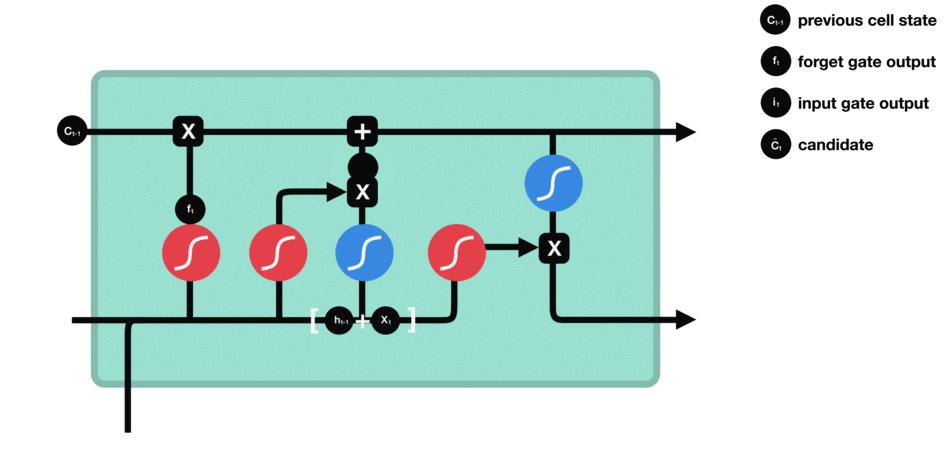
Input Gate - Imagen de Michael
Toma el input vector y la short term memory y los une. Entonces ignora ciertas partes para conservar únicamente los datos importantes de él.
Para combinar el input vector con la short term memory:
- Se forma una matriz con el input vector y la short term memory.
- Este se multiplica por la matriz de ponderaciones.
- Se añade el término de bias.
- Se aplica la función de activación tanh
Para ignorar parte de él:
Se multiplica por un ignore factor (it), es decir, un vector que mulplica cada elemento. Para calcularlo:
Se repite el procedimiento anterior, sin embargo, se utiliza la función de activación sigmoide (para mantener los valores entre 0 y 1) y tanto un nuevo vector de ponderaciones como un nuevo término de bias.
\[i_t = \sigma(W_i * [STM_{t-1}, E_t] + b_i)\]
Representación matemática de la input gate - Imagen de Udacity
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}