Teoría

Escrito por
5 minutos de lectura
Image Captioning
El principal objetivo de esta sección es aprender cómo trabajar en conjunto con una CNN y una RNN para así obtener el texto que definirá a la imagen (caption). Este pie de foto puede ayudar a una persona ciega o con poca visión quien debe confiar en los sonidos y el texto para describir la escena. Además, en el desarrollo web es una buena práctica señalar el contenido que aparece en la imagen.
Un dataset que se suele utilizar en un “captioning model” es el COCO Dataset (Common Objects in Context). Contiene una gran variedad de imágenes con 5 captions asociadas a ellas y etiquetas para los segmentos de la imagen.
Descripción del modelo a utilizar
Se dota a la CNN de una image como input y el output de esta red es conectado con el input de la RNN lo cual nos permitirá generar textos descriptivos.
Encoder
Al final de una CNN como ResNet se encuentra un clasificador softmax. Este lo deberemos eliminar ya que nuestra misión no es clasificar la imagen sino tener un feature vector que representen el contenido espacial de la imagen. Por la función que realiza la CNN, a esta red se la denomina encoder.
Puede resultar útil pasar el output de la CNN a través de una fully-connected o linear layer adicional antes de ser utilizado como input para la RNN.
Decoder
El output de la CNN entonces será introducido a la RNN que se encargará de convertir el feature vector procesado en lenguaje natural. Por esa razón a esta red se la conoce como decoder.
Nuestro objetivo con la RNN será predecir palabras en base a las anteriores. Sin embargo, las redes neuronales no trabajan bien con cadenas de texto, necesitan un output numérico para así llevar a cabo de forma exitosa el backpropagation y aprender a producir outputs similares. Así que tenemos que transformar los textos asociados a las imágenes en una lista de tokenize words.
Tokenización
La tokenización transforma cualquier cadena de texto en una lista de números enteros. Para conseguir esto su procedimiento es el siguiente:
-
Itera a través de todos los training captions y crea un diccionario que relaciona todas las palabras únicas en un índice numérico. A estas palabras del diccionario las conoceremos como el vocabulario. Este vocabulario suele incluir unos tokens especiales como <start> y <end> que indican el comienzo y el final de una frase.
[<start>, ‘a’, ‘person’, ‘surfing’, <end>]
-
La lista de tokens de una frase en convertida en una lista de números enteros mediante el diccionario creado anteriormente.
[0, 3, 40, 287, 1]
-
La lista de enteros deberán pasar por la embedding layer que transforma cada palabra de un caption en un vector del tamaño deseado.
Una de las mejores maneras para realizar la word tokenization es importando la librería NLTK (Natural Language Toolkit).
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
# Split text into words using NLTK
# "Dr. Dre is the best man alive" -> ["Dr.", "Dre", "is", "the", "best", "man", "alive"]
words = word_tokenize(text)
# Split text into sentences
# Dr. Dre knows it. He's not dumb. -> ["Dr. Dre knows it", "He's not dumb."]
sentences = sent_tokenize(text)
Entrenamiento del decoder
El decoder estará compuesto de células LSTM ya que son apropiadas para recordar largas secuencias de palabras.
Esta red tiene 2 responsabilidades:
- Recordar la información espacial del feature vector dado como input.
- Predecir la siguiente palabra.
El output de la RNN debe comenzar por el token <start> y finalizar con el token <end>.
El procedimiento que esta red sigue es:
- Obtiene la palabra y la pasa por la embedding layer.
- Computa la palabra mediante la o las células LSTM.
- El output es suministrado a una linear y softmax layer para así obtener cuál es la siguiente palabra en la oración, un procedimiento muy parecido a la clasificación de una CNN.
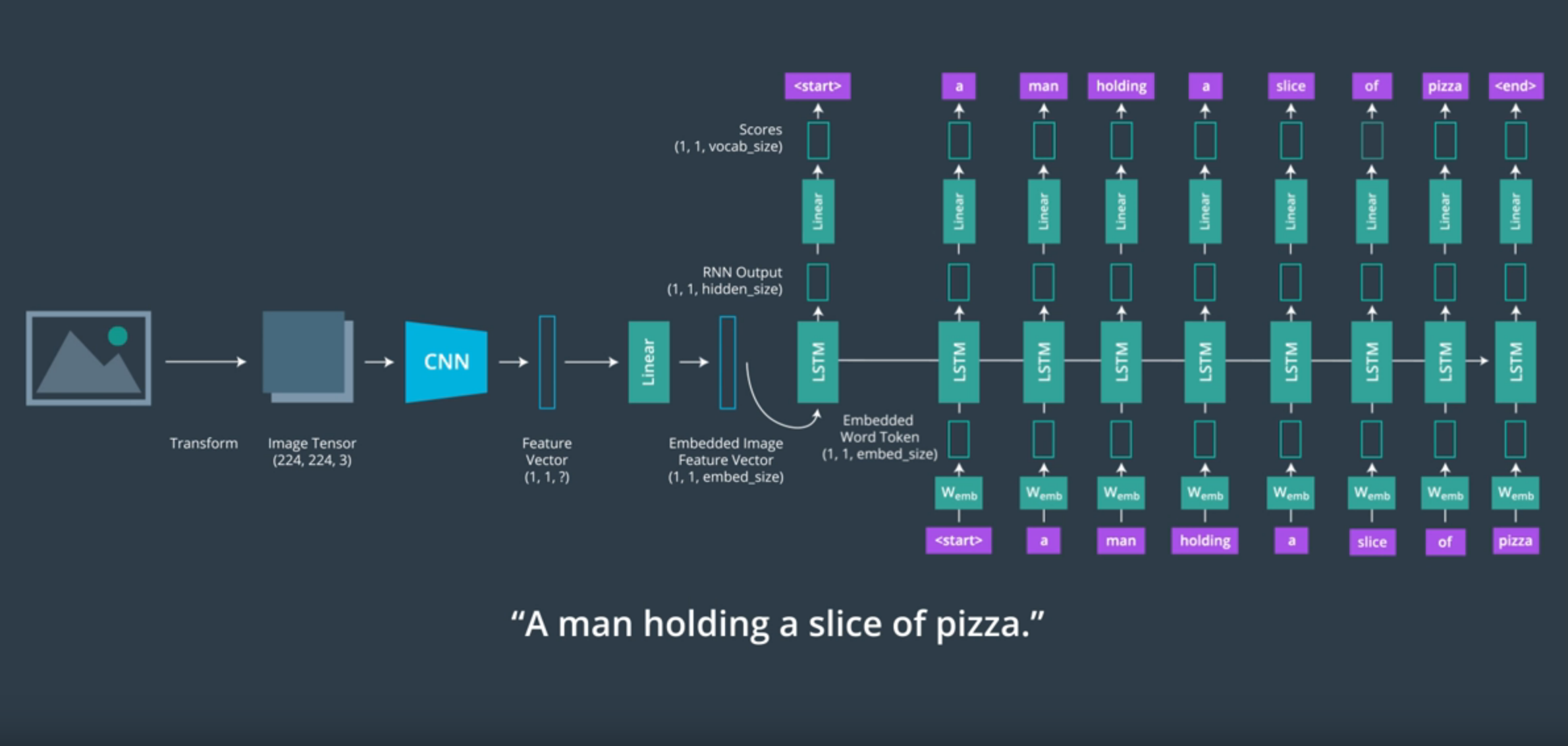
Representación de la RNN y CNN - Imagen de Udacity
Este proceso también se puede aplicar a vídeos (los cuales no dejan de ser una serie de imágenes), lo que cambia en este caso es la extracción de features.
El problema en esta situación es que la CNN produciría varios feature vectors y la RNN solo acepta un único input. Por lo tanto es necesario condensar el conjunto de feature vectors en uno solo. Una forma de hacer esto es tomar un promedio de todos los feature vectors creados por el set de frames del vídeo.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}