Teoría

Escrito por
4 minutos de lectura
Representación y clasificación de imágenes
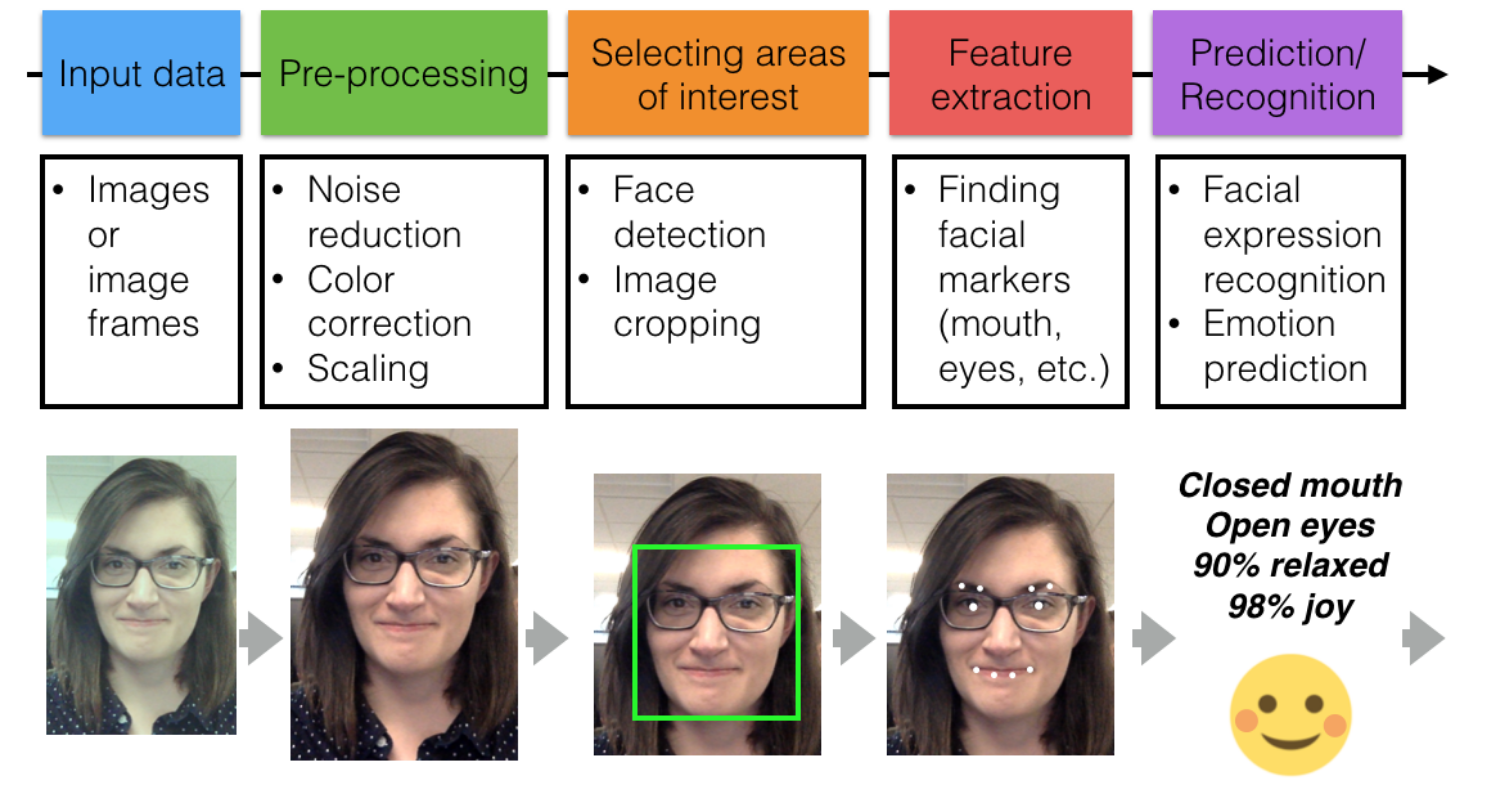
¿Cuáles son los pasos que sigue una aplicación de computer vision para reconocer patrones en la imagen?
-
Pre-procesado: Consiste en estandarizar las imágenes de entrada para así analizarlas de la misma forma, teniendo cada una la misma calidad y detalle que el resto.
-
Selección de las áreas de interés.
-
Extracción de características.
-
Predicción/Reconocimiento de patrones.
Ver “day_night_image_classifier/classifier.ipynb” para observarlo en código
Visión superficial de cómo entrenar un modelo para reconocer patrones en una imagen.
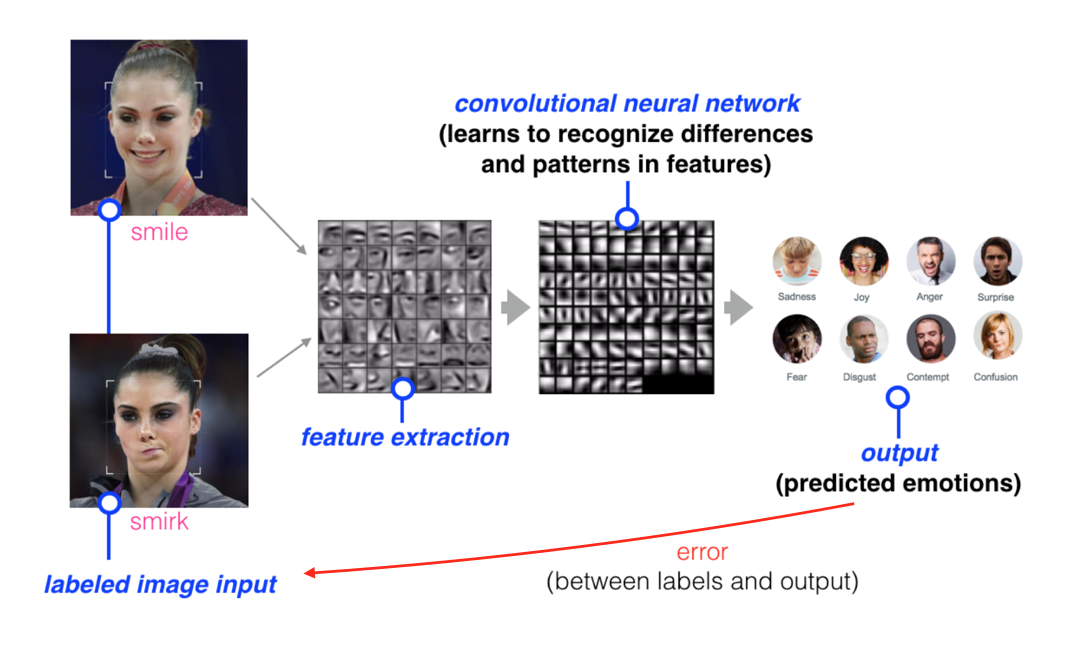
Para hacerlo, podemos proporcionar a la red neuronal un set de imágenes etiquetadas que serán comparadas con la etiqueta del output predicho. Ej.: Si dotamos a la red de la imagen de una persona sonriendo, lo podemos comparar con la respuesta de la que nos dota al modelo al hacer la predicción.
Al hacer esto, la red puede monitorear los errores que hace y auto-corregirse modificando cómo encuentra y prioriza los patrones de la imagen. De esta forma, el modelo podrá caracterizar nuevos datos de imágenes que se encuentren si etiquetar.
¿Cómo representar una imagen numéricamente?
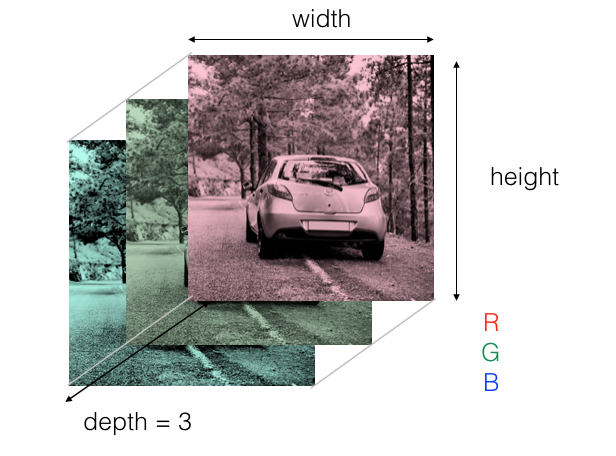
Si tenemos una imagen de 639 px de ancho y 426 de alto y queremos obtener un píxel de la imagen podríamos coger el (190, 375) y así su valor, lo cual la red utilizará para ser entrenada.
Muchas veces nos puede ser útil convertir nuestras imágenes a una escala de grises para mejorar el rendimiento de nuestro modelo. Sin embargo, en ocasiones la escala de grises no nos proporciona la suficiente información (Ej. distinguir una línea blanca de una carretera de una amarilla).
Ver “Images as Grids of Pixels.ipynb”.
Umbral de color
Consiste en cambiar el color de fondo de un objeto a otro (ej. cuando se cambia la pantalla de fondo verde en un cine por unas imágenes generadas digitalmente).
Seleccionar un umbral con un rango de colores funciona bien cuando el color es estático (utilizar un color picker para ello), sin embargo, si la luz cambia y hay sombras la selección del color fallará.
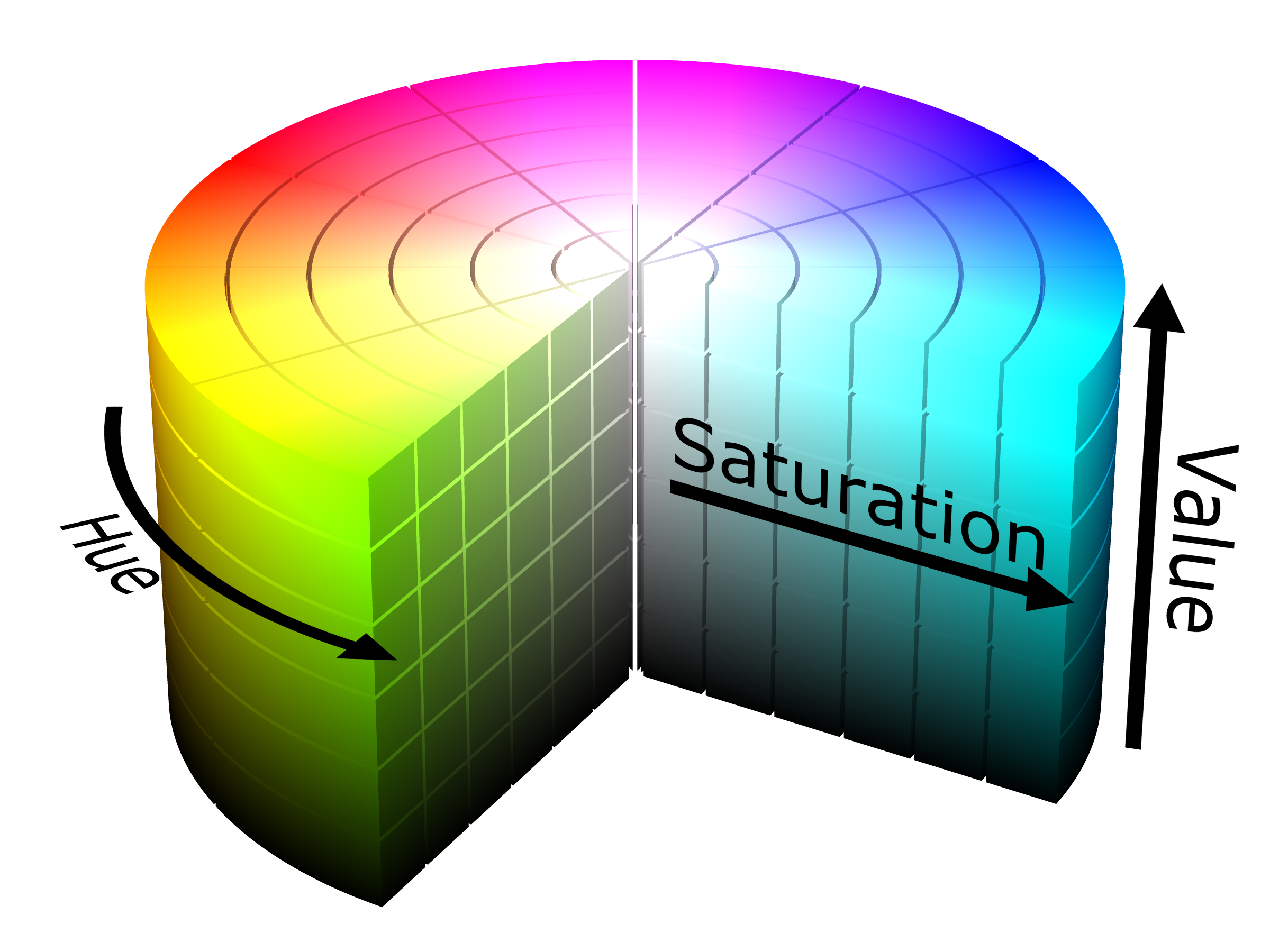
En el formato de color HSV:
-
El canal Hue (H) se mantiene consistente ante la presencia de sombras o de un exceso de luminosidad.
-
El canal Value (V) presenta una gran variación frente a diferentes condiciones de luz.
Por lo tanto, debemos tener presente el formato HSV ante imágenes con gran variación de luminosidad.
Ver “Color Threshold.ipynb”.
Distinción entre imágenes
Hay gran cantidad de características que se pueden distinguir entre unas imágenes u otras, a estos rasgos los denominamos features. Este es un componente medible de una imagen o un objeto que, idealmente, es único y reconocible bajo ciertas condiciones: La condición puede ser la variación de la luz o del ángulo de la cámara.
Las imágenes pueden estar etiquetadas con valores de categorización (como “perro”, “día”,…) propias principalmente de muchos de los datasets creados o con etiquetas numéricas que permiten ser fácilmente comparadas y guardas en la memoria, además de que muchos algoritmos de ML no usan datos categorizados.
Las etiquetas numéricas se dividen en dos enfoques:
- Integer Encoding: Asignar a cada categoría un entero (day = 1, night = 0). Es una buena forma de separar datos binarios como en el ejemplo.
- One-hot Encoding: Se suele usar cuando hay más de dos valores para separar. Una etiqueta one-hot constituye una lista en 1D cuya longitud es la del número de clases. Ej.: En una lista con [“cat”, “tiger”, “hippopotamus”, “dog”] la lista tendría 4 elementos con 3 ceros y 1 uno indicando qué clase es una cierta imagen. [0, 1, 0, 0] representaría la clase “tiger”.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}