Teoría

Escrito por
6 minutos de lectura
Hiperparámetros
Los hiperparámetros son aquellos valores que debemos seleccionar nosotros mismos antes de aplicar un algoritmo de aprendizaje.
El problema de estos es que no hay una serie de valores para los hiperparámetros que funcionen bien en todas las tareas, sino que según la tarea o el dataset los valores óptimos para los hiperparámetros variarán y nos deberemos de encargar de encontrarlos.
Los hiperparámetros pueden ser clasificados en dos categorías:
-
Hiperparámetros de optimización:
Variables más relacionadas con los procesos de optimización y de entrenamiento que del modelo en sí.
Incluye:
- Learning rate.
- Minibatch size.
- Número de iteraciones en el entrenamiento o épocas.
-
Hiperparámetros del modelo:
Variables más relacionadas con la estructura del modelo.
Incluye:
- Número de capas y de unidades ocultas.
- Hiperparámetros de arquitecturas específicas.
Algunos de estos hiperparámetros nombrados los trataré a continuación:
Learning rate
Es el hiperparámetro más importante y uno debería siempre asegurarse de que ha sido calibrado. - Yoshua Bengio
Un buen valor para comenzar es 0.001.
Se recomienda probar con los siguientes y ver con cual reacciona mejor la red neuronal:
0.1, 0.01, 0.001, 0.0001, 0.00001, 0.000001
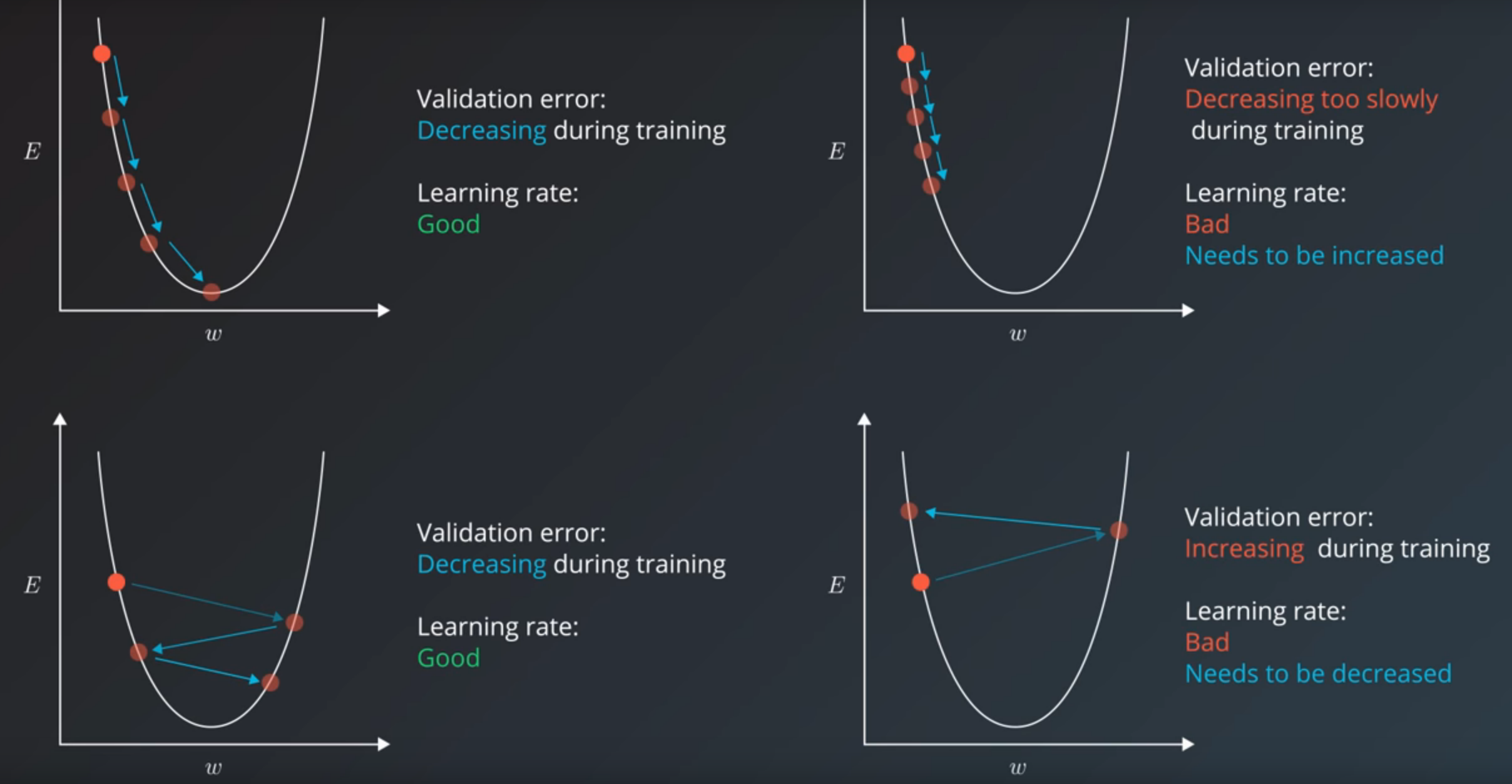
Eje x: ponderaciones | Eje y: Error
Representación del learning rate - Imagen de Udacity
Learning rate decay: Es utilizado cuando el learning rate es alto. El algoritmo de entrenamiento se encarga de disminuir el learning rate a lo largo del entrenamiento. A este se le denomina adaptive learning rate.
Minibatch Size
Tipos:
-
Online training (Or stochastic):
Le dotamos a nuestro modelo de un único ejemplo de nuestro dataset en cada paso de entrenamiento. Y utilizando este, realizar un forward pass, calcular el error y realizar el backpropagation.
-
Batch training:
Dotar a nuestro modelo del dataset entero en cada training step.
Entendiendo esto, podemos definir el minibatch size como el número de training examples. Este puede adoptar valores desde uno (online training) al número de ejemplos del dataset (batch training).
El conjunto de valores con los que se suele probar son los siguientes:
1, 2, 4, 8, 16, 32, 64, 128, 256.
Valores pequeños: [1, 2, 4, 8, 16]
Valores muy grandes: [512, 1024, 2048]
32 suele ser un buen candidato. Un minibatch size mayor puede ser mejor, sin embargo, hace que necesite más memoria y, en general, más recursos. Por lo tanto, algunos de los “out of memory errors” de Tensorflow pueden ser evitados disminuyendo el minibatch size.
Un minibatch size pequeño produce mayor ruido en los cálculos del error. Esto puede llevar a que el proceso de entrenamiento se quede en un mínimo local en vez de en el global.
Así que unos buenos valores con los que experimentar son: [32, 64, 128].
Número de iteraciones
Para escogerlo, debemos fijarnos en el error de validación. Lo que perseguimos en tener nuestro modelo entrenando mientras el error de validación siga decreciendo.
Aun así, también podemos utilizar una técnica llamada early stopping para determinar cuando parar de entrenar nuestro modelo. Este funciona monitoreando el error de validación y frenando el entrenamiento cuando deje de decrecer.
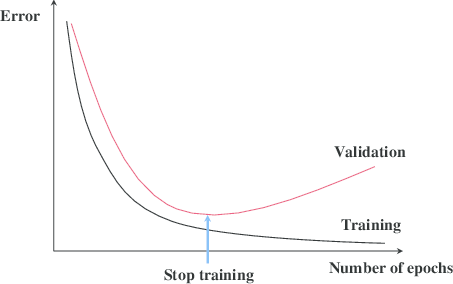
Representación gráfica del early stoppig - Imagen de El misterio del Early Stopping
Sin embargo puede que el validation error simplemente esté pasando por un “bache” tras el cual volverá a decrecer. Para esto le indicamos que se frene el entrenamiento si el error no ha decrecido en los próximos 10 a 20 pasos.
Número de capas y de unidades ocultas.
La claves escoger un número de hidden units que sea lo suficientemente largo. Cuanto más compleja sea la función, más capacidad de aprendizaje será necesaria. La forma de medir esta “capacidad de aprendizaje” es con el número y la arquitectura en la que están dispuestas las hidden units.
Pero si dotamos a nuestro modelo de mucha capacidad tenderá al overfitting al intentar memorizar los datos. Para evitarlo podemos reducir el número de hidden units, añadir más capas de dropout o realizar una L2 regularization.
Aunque un número mayor de hidden units que el ideal no resulta en un problema, siempre y cuando no sea mucho mayor.
Según el investigador de Stanford Andrej Karpathy, una red neuronal de tres capas mejorará en resultados a una de dos. Pero al aumentar el número de capas a más de tres tampoco se notará mucho en los resultados. La excepción en este caso son las CNN, en las cuales cuanto mayor sea el número de capas, mejor será el resultado.
Hiperparámetros de una RNN
Dos elecciones principales que tenemos que escoger a la hora de construir una RNN son:
-
El tipo de neurona o célula.
Una neurona LSTM o una tradicional de la RNN o una GRU. Aunque en general las células de LSTM o de GRU actúan mejor que una vanilla RNN cell. La recomendación es probar ambas y ver cuál es mejor para nuestro dataset (no es necesario probarlo para todo, simplemente para un subconjunto aleatorio de nuestros datos).
-
La cantidad de capas. Aunque por lo mencionado antes un buen valor de capas es 3, en tareas como speech recognition se ha visto que 5 o 7 capas pueden arrojar mejores resultados.
También en otros factores dependiendo del tipo de inputs. Por ejemplo si estos son palabras, entonces deberemos fijarnos tambien en la “embedding dimensionality”.
Otros recursos para aprender sobre hiperparámetros son los siguientes:
- Practical recommendations for gradient-based training of deep architectures por Yoshua Bengio.
- Deep Learning book - chapter 11.4: Selecting Hyperparameters por Ian Goodfellow, Yoshua Bengio, Aaron Courville.
- Neural Networks and Deep Learning book - Chapter 3: How to choose a neural network’s hyper-parameters? por Michael Nielsen.
- Efficient BackProp (pdf) por Yann LeCun.
Recursos más especializados:
- How to Generate a Good Word Embedding? por Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao.
- Systematic evaluation of CNN advances on the ImageNet por Dmytro Mishkin, Nikolay Sergievskiy, Jiri Matas.
- Visualizing and Understanding Recurrent Networks por Andrej Karpathy, Justin Johnson, Li Fei-Fei.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}