Teoría

Escrito por
11 minutos de lectura
Tipos de Features y Segmentación de la Imagen
Tipos de features:
- Bordes: Áreas con un gradiente de gran intensidad. (Ver “Convolutional-Filters-Edge-Detection.md” para entenderlo).
- Esquinas: Se encuentran en la intersección de dos bordes.
- Blobs (Manchas): Áreas con una gran luminosidad o una única textura.
Entre estos tres, las esquinas coinciden exactamente con la imagen, por lo que son buenos features que nos servirán para interpretar la imagen.
¿Cómo localizar una esquina?
Para ello debemos seguir 3 pasos:
-
Calculamos el gradiente de una pequeña sección de la imagen utilizando los operadores sobel-x y sobel-y (sin aplicar el umbral binario).
-
Para calcular la magnitud utilizamos: \(sqrt(sobel_x^2+sobel_y^2)\)
-
Repetir esta práctica trasladando la sección por el resto de la imagen, calculado el gradiente de cada una. Cuando se produzca una gran variación en la dirección y la magnitud del gradiente habremos detectado un borde.
Para más información ver Harris Corner Detection y el archivo “harris-corner-detection.ipynb”.
Dilatación y Erosión

Imagen de Udacity
Dilatación
Aumenta las áreas blancas y brillantes de una imagen añadiendo píxeles a los límites conocidos del objeto. Se utiliza la función cv2.dilate.
# Lee la imagen. La bandera 0 la convierte en escala de grises
image = cv2.imread(‘j.png’, 0)
# Crea un kernel de 5x5 de unos
kernel = np.ones((5,5),np.uint8)
# Dilatación de la imagen
dilation = cv2.dilate(image, kernel, iterations = 1)
Erosión
Es el proceso opuesto a la dilatación: Elimina los píxeles que se encuentran en los límites conocidos del objeto y reduce el tamaño del mismo. Se utiliza la función cv2.erode.
erosion = cv2.erode(image, kernel, iterations = 1)
Opening
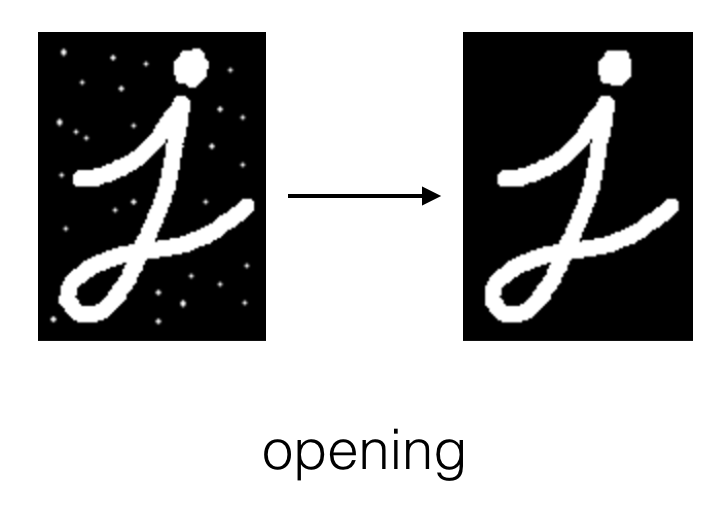
Imagen de Udacity
Consiste en una erosión para eliminar el ruido del fondo del objeto seguido de una dilatación para volver a agrandar el objeto tras la erosión. Es decir, es una forma de eliminar el ruido del fondo de la imagen mediante la función cv2.morphologyEx y el parámetro cv2.MORPH_OPEN.
opening = cv2.morphologyEx(image, cv2.MORPH_OPEN, kernel)
Closing
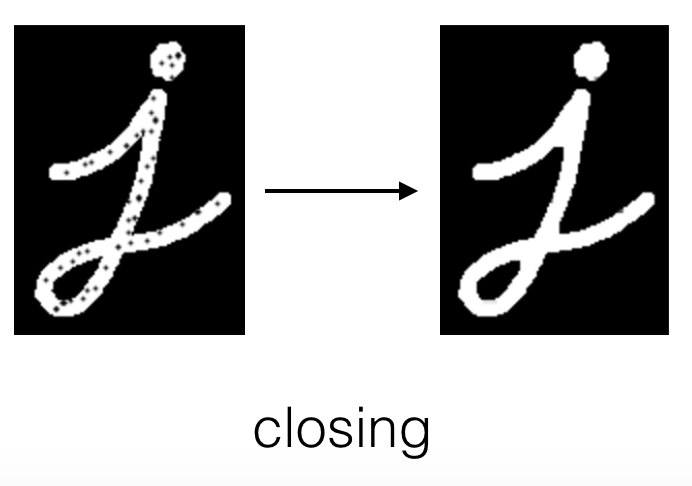
Imagen de Udacity
Consiste en una dilatación para eliminar el ruido del objeto seguido de una erosión para volver a encoger el objeto tras la dilatación. Es decir, es una forma de eliminar el ruido del objeto mediante la función cv2.morphologyEx y el parámetro MORPH_CLOSE.
opening = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernel)
Segmentación de la imagen
La agrupación o segmentación de las imágenes en sus diferentes partes es conocido como la segmentación de imagen.
Algunas formas para segmentar una imagen:
- Usar los contornos para dibujar los límites alrededor de las diferentes partes de una imagen.
- Agrupar los datos de las imágenes mediante una medida de color o textura similar.
Image Countering
Esta es una técnica utilizada para hallar los límites que se encuentran cerrados totalmente creando curvas que siguen los bordes a través de los límites. Ej. en una mano no queremos las rayas y las huellas de la mano, sino los dedos y la muñeca, es decir, el contorno.
De esta forma nos proporcionan bastante información sobre la forma del límite del objeto.
En OpenCV esta técnica es muy útil cuando se encuentra un objeto sobre un fondo negro, por lo que primero tendremos que convertir nuestra imagen a una imagen binaria, es decir, sólo con píxeles blancos y negros. Para ello utilizaremos un simple umbral o el canny edge detector. Y entonces ya podremos utilizar los bordes de esta imagen para formar el contorno.
En código, una vez tenemos nuestra imagen en escala de grises podemos hacer lo siguiente:
# Crea una imagen binaria mediante un umbral (binary threshold)
# Todos los px contenidos entre 225 y 255 serán convertidos a 0, es decir, negro
# cv2.THRESH_BINARY_INV es el algoritmo para aplicar el umbral
retval, binary = cv2.threshold(gray_image, 225, 255, cv2.THRESH_BINARY_INV)
# Buscar los contornos de la imagen binaria con el umbral aplicado
# cv2.RETR_TREE es un modo de recuperación del contorno de tipo árbol
# cv2.CHAIN_APPROX_SIMPLE es el método de aproximación del contorno de tipo cadena
# El output es listado en la variable hierarchy, la cual es muy útil cuando
# tenemos muchos contornos juntados unos con otros
retval, contours, hierarchy = cv2.findCountours(binary, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# Pintar todos los contornos en la imagen original
# -1 se refiere a todos los contornos
# (0, 255, 0) se refiere al color de la línea
# 2 se refiere al grosor de la línea
all_contours = cv2.drawContours(image_copy2, contours, -1, (0, 255, 0), 2)
Gracias a este contorno podemos extraer información como la forma, su área, su centro, su perímetro o el rectángulo límite (este último lo hemos visto anteriormente cuando se creaba un rectángulo para señalar la cara de una persona). Estos son conocidos como los contour features.
Contour features
-
Orientación: Es el ángulo al cual un objeto se dirige. Para buscar el ángulo, primero tenemos que buscar una elipse la cual se ajuste al contorno y así extraer el ángulo de la forma.
(x,y), (MA,ma), angle = cv2.fitEllipse(selected_contour)El valor del ángulo está tomado en ángulos respecto al eje x. Un valor de 0 significaría una línea plana y un valor de 90 que está apuntando hacia el norte.
-
Rectángulo límite:
# Buscar el rectángulo límite de un contorno seleccionado x,y,w,h = cv2.boundingRect(selected_contour) # Dibujar este rectángulo como una línea de color morado box_image = cv2.rectangle(contours_image, (x,y), (x+w,y+h), (200,0,200),2) # Cortar utilizando las dimensiones del rectángulo límite (x, y, w, h) cropped_image = image[y: y + h, x: x + w]
Para verlo aplicando, abrir el archivo “contour-detection-features.ipynb”.
K-means
K-Means es un algoritmo de aprendizaje no supervisado, es decir, no es necesario etiquetar la información sino que el algoritmo por sí solo se encarga de buscar grupos y patrones similares sobre un dataset sin etiquetar. Al darle un dataset al algoritmo, también debemos decirle en cuantos k clusters queremos que se descomponga (Esto es el número de grupos).
K-means Clustering
Separa una imagen en segmentos agrupando los puntos que comparten rasgos similares.
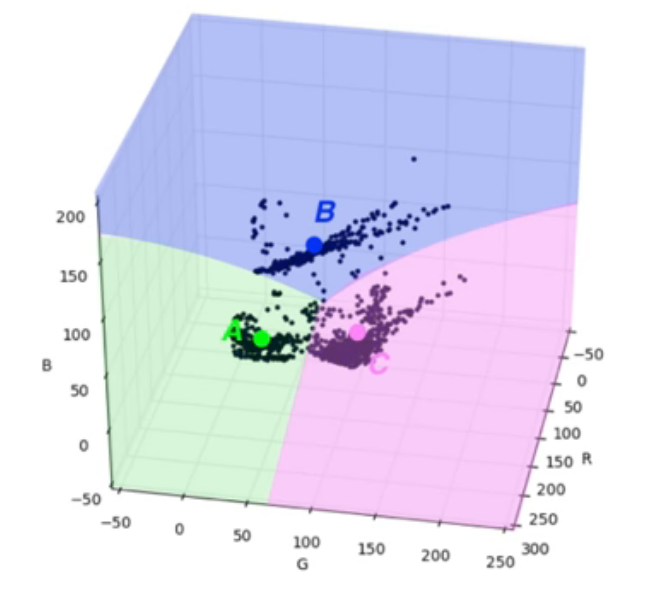 Imagen de Udacity
Imagen de Udacity
Si le decimos al algoritmo que separe el dataset de una imagen rgb en 3 clusters, el procedimiento que hará será el siguiente:
- Escoger tres puntos k centrados de forma aleatoria.
- Asignar cada punto a un cluster basado en la cercanía al punto central.
- Toma la media de todos los valores que se encuentran en cada cluster, convirtiéndose estos valores medios en el nuevo punto central de cada cluster.
- Se repiten los pasos 2 y 3 hasta que los valores medios calculados nuevamente casi coincidan (puede haber un margen de error de 1px) con los anteriores, es decir, hasta que se llegue a la convergencia.
Para preparar el dataset (la imagen) para k-means:
# Cambiar la forma de la imagen en un array de 2D y 2 valores de colores (RGB)
pixel_values = image_copy.reshape((-1, 3))
# Convertir a tipo flotante
pixel_values = np.float32(pixel_values)
Para implementar k-means clustering:
# Definir el criterio que indica al algoritmo cuando parar
# 10 representa el máximo número de intentos
# 1.0 representa el margen de error
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
k = 2
# En el siguiente caso, None representa las banderas que queramos
# 10 representa el número de intentos
retval, labels, centers = cv2.kmeans(pixel_values, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)
# Convertir data en valores de 8 bits
centers = np.uint8(centers)
segmented_data = centers[labels.flatten()]
# Cambiar la forma de la imagen a sus dimensiones originales
segmented_image = segmented_data.reshape((image_copy.shape))
labels_reshape = labels.reshape(image_copy.shape[0], image_copy.shape[1])
Para ver el k-means clustering implementado, abrir el archivo “k-means-clustering.ipynb”.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}