Teoría

Escrito por
11 minutos de lectura
Feature Vectors
Para identificar objetos similares al cual hemos seleccionado podemos escoger un set de features para así definir la forma de la montaña, agrupar las formas en un array y usar el set para crear de esta manera un detector de montañas.
Para obtener vectores de características podemos observar la dirección de varios gradientes que se encuentran alrededor del punto central de una imagen, de esta forma obtendríamos una representación robusta de la forma del objeto.
Ejemplos de gradient features:
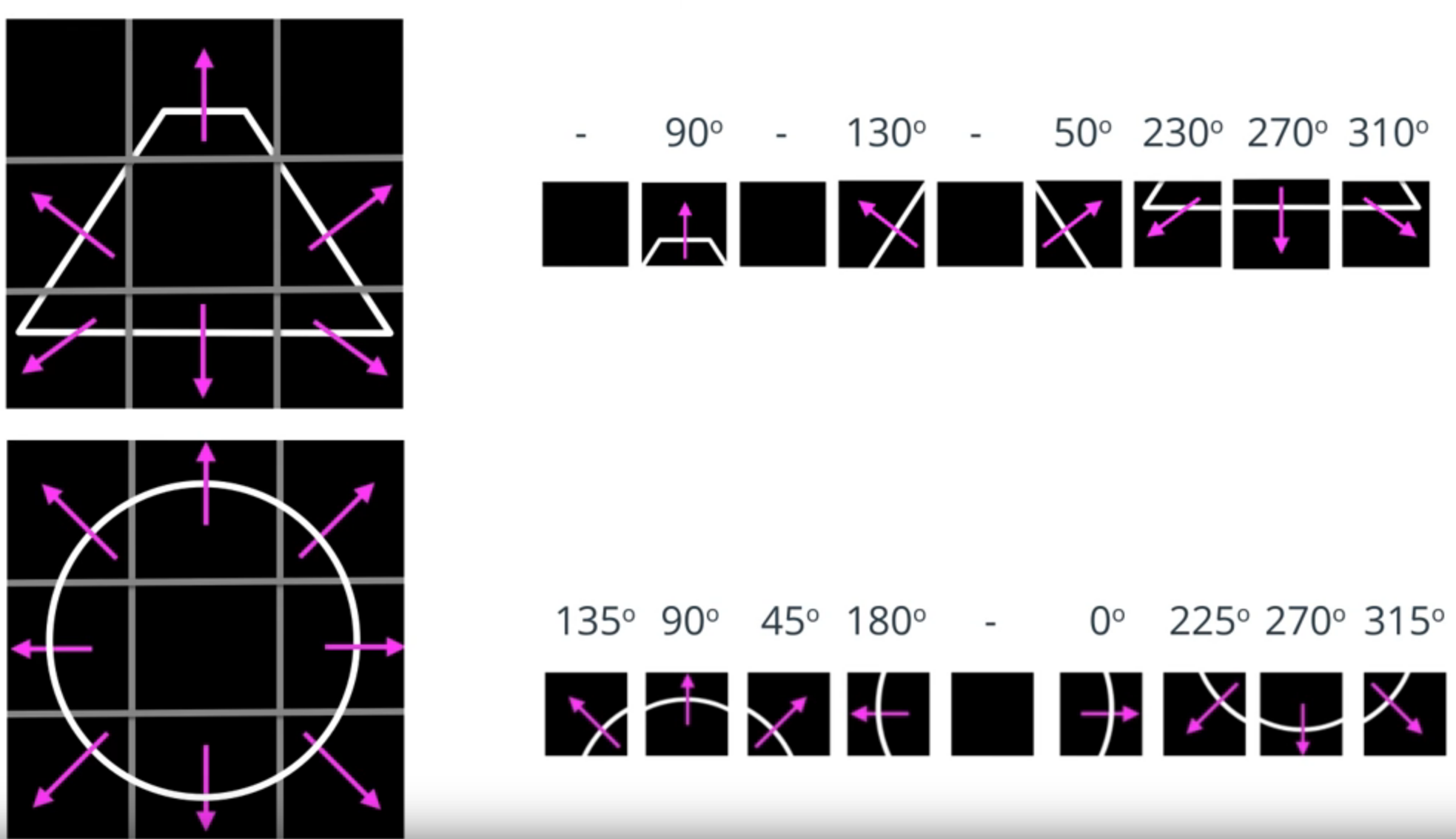
Imagen de Udacity
Oriented FAST and Rotated BRIEF (ORB) Algorithm
Es utilizado para crear rápidamente vectores de características de los puntos principales de una imagen para así identificar objetos en ella. El ser veloz nos ayuda para las aplicaciones en tiempo real como la realidad aumentada, la detección de un coche de otros vehículos, etc.
Además, es inmune a una iluminación que empeore la imagen y a transformaciones de la imagen como rotaciones.
Su procedimiento es el siguiente:
- Localiza en una imagen sus keypoints, es decir, pequeñas regiones de ella que la distinguen de otras. Un ejemplo de estos son las esquinas donde los valores de los píxeles cambian drásticamente de claro a oscuro o viceversa.
- Después, el algoritmo calcula los vectores binarios de características (ya que sólo contienen 0s y 1s) correspondientes para cada keypoint. Al conseguir varios vectores de características es más sencillo identicar una área más grande e incluso un objeto en específico de una imagen.
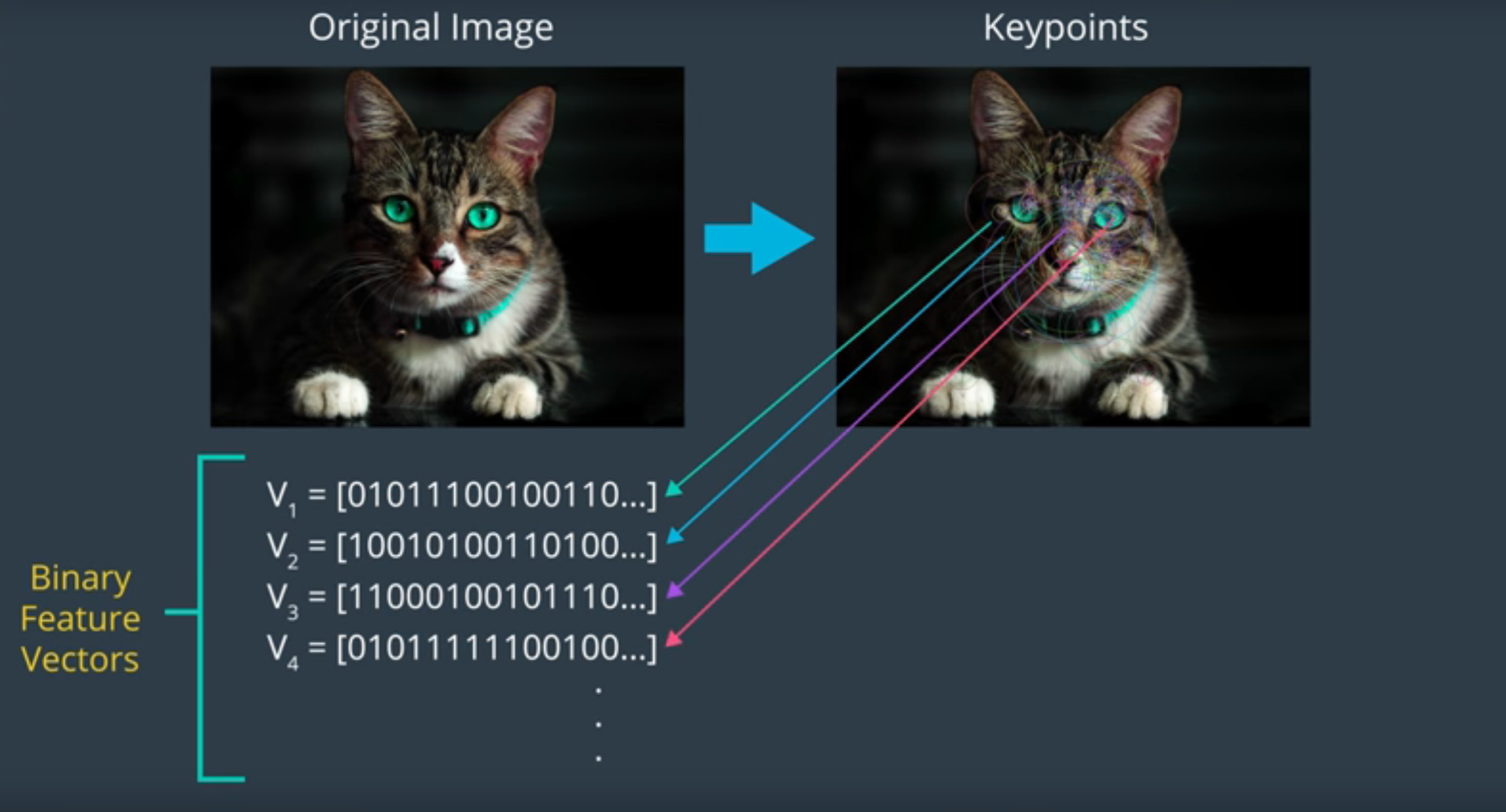
Imagen de Udacity
Features from Accelerated Segments Test (FAST)
Primer paso del algoritmo ORB.
Se encarga de rápidamente seleccionar los keypoints comparando los niveles de luminosidad del área de píxeles dada (IP = luminosidad de un píxel).
Procedimiento:
- Compara la luminosidad de un píxel p de un conjunto de 16 píxeles que le rodean dibujando así un círculo alrededor de él.
- Tras definir un valor para el umbral h, cada píxel del círculo es ordenado en 3 clases:
- Píxeles luminosos: Superen el IP de p más h.
- Píxeles similares: Estan entre IP de p más h y IP de p menos h.
- Píxeles oscuros: Se encuentran por debajo del IP de p menos h.
- Entonces, p será seleccionado como un keypoint si 8 o más píxeles de ese círculo son o luminosos o oscuros.
La razón por la que FAST es tan eficiente es porque se aprovecha del hecho de que los mismos resultados pueden ser conseguidos comparando p a únicamente 4 píxeles equidistantes del círculo en vez de 16 píxeles rodeándole. De esta manera, p se convierte en un keypoint si hay al menos 2 píxeles luminosos o oscuros alrededor de él. Esto reduce el tiempo que se necesitaría para buscar en una imagen entera los keypoints.
Los keypoints hallado por el algoritmo FAST nos proporcionan información sobre la localización de un objeto definiendo los bordes en la imagen. Sin embargo, aunque nos proporcionen la localización de los bordes, no nos dan ni su dirección ni el cambio de intensidad.
Binary Robust Independet Elementary Features (BRIEF)
Segundo paso del algoritmo ORB.
Con los keypoints ya encontrados por el algoritmo FAST el algoritmo BRIEF crea los binary feature vectors. Al ser binarios puede ser almacenados de una manera eficiente en la memoria y pueden ser computados mucho más rápido, así pueden ser utilizados hasta en dispositivos con recursos muy limitados como un smartphone.
Procedimiento:
-
Inicia desenfocando la imagen con un kernel Gaussiano para prevenir al descriptor (el vector) de ser muy sensible al ruido con altas frecuencias.
-
Después, dado un keypoint, el algoritmo BRIEF selecciona un par de píxeles dentro de una sección cercana definida (conocida como parche, un cuadrado de ciertos píxeles) alrededor de él.
-
- El primer píxel es dibujado de una distribución gaussiana centrada alrededor del keypoint y con la desviación estándar de sigma.
- El segundo píxel del par aleatrorio es dibujado de una distribución gaussiana centrada alrededor del keypoint y con la desviación estándar de sigma sobre 2.
Esto mejore la tasa de coincidencia de features.
-
BRIEF entonces comienza a formar el descriptor binario para el keypoint comparando la luminosidad de los dos píxeles de la siguiente manera:
- Si el primer píxel es más brillante que el segundo: Éste le asigna un valor de 1 al bit correspondiente del descriptor (V_1 = [1]).
- Sino le asigna el valor de 0.
-
Para el mismo keypoint vuelve a realizar los pasos 2, 3 y 4, asignando así más bits al descriptor hasta la longitud en bits del vector (256 bits).
Scale and Rotation Invariance
Dada una imagen, el algoritmo ORB empieza por construir una imagen piramidal: Una representación multiescala de una sola imagen que consiste en una secuencia de imágenes de la primera pero en resoluciones distintas. Por lo que cada nivel en la pirámide corresponde a una imagen con una resolución inferior a la anterior por un factor de 2 (el segundo nivel es 1/2 el primero).
Tras crear la imagen piramida, el algoritmo ORB aplica el algoritmo FAST para así localizar rápidamente los keypoints en las imágenes de cada nivel. De esta manera, ORB consigue no variar parcialmente según la escala. Esto es de mucha importancia porque seguramente los objetos no van a aparecer del mismo tamaño en cada imagen (por ejemplo en un vídeo).
ORB asigna una orientación a cada keypoint dependiendo en los cambios de intensidad que se producen en cada keypoint, el procedimiento es el siguiente:
-
Selecciona la imagen en el nivel 0 de la pirámide.
-
Calcula la orientación de los keypoints computando el centroid de intensidad dentro de una caja con un keypoint de centro. El centroid de intensidad es la posición de la media de la intensidad de los píxeles dado un cierto parche.
-
Una vez calculado el centroid de intensidad, la orientación del keypoint es obtenida dibujando un vector desde el keypoint hasta el centroid de intensidad. Se dibujan los ejes con el keypoint como eje de coordenadas y según el cuadrante donde se encuentre el vector será la orientación del keypoint.
-
ORB repite los pasos 2 y 3 para el resto de niveles de la pirámide.
Es importante tener en cuenta que el tamaño del parche no se reduce en cada nivel.
Después de haber localizado y dado una orientación a los keypoints, ORB utiliza una versión modificada de BRIEF (rBRIEF, Rotation-Aware Brief) para crear el mismo feature vector para los keypoints sin importar la orientación del objeto. Esto hace al algoritmo ORB invariante ante rotaciones de la imagen.
El set de todos los feature vector de todos los keypoints encontrados en una imagen se denomina ORB descriptor.
Feature Matching
Cómo actúa el algoritmo ORB para, mediante los keypoints y su dirección ya calculada anteriormente, reconocer otros objetos similares partiendo de este (ej. detección de caras). La primera imagen la llamamos la imangen de entrenamiento y la segunda imagen en la que queremos llevar a cabo el feature matching se denomina query image.
Procedimiento:
-
Calculamos el ORB descriptor de nuestra imagen de entrenamiento y de la query image.
-
Llevamos a cabo el keypoint matching comparando sus correspondientes descriptores. Para ello utilizamos una función de matching para así encontrar los keypoints que se encuentran cercanos entre ambas imágenes. El trabajo de la función es ver si los feature vectores contienen un orden similar de 1s y 0s.
La métrica utilizada en algoritmos binarios como ORB es el hamming metric porque tiene un rendimiento muy veloz. Esta métrica mide la calidad de la similitud entre dos keypoints cotando el número de bits que no tienen en común ambos descriptores binarios.
El par de keypoints de la query image que más similitudes tenga con el de la imagen de entrenamiento se considera el mejor match.
-
Si la función de matching nos da un número de coincidencias por encima del umbral de coincidencia, podemos concluir que el objeto se encuentra en el frame.
El mesh threshold es un parámetro libre que nosotros debemos de seleccionar.
El algoritmo de ORB es muy útil en la detección de caras ya que la variación es pequeña entre ellas, sin embargo no sería tan buena idea utilizarlo para un reconocimiento de objetos más a nivel general como la detección de peatones ya que varía especialmente en su ropa y movimiento.
Para ver el algoritmo implementado, abrir el archivo “orb.ipynb”.
Histogram of Oriented Gradients (HOG)
Un histograma es una representación gráfica de una distribución de datos. En este caso es una gráfica de barras en el que cada barra se denomina “bin”.
Oriented gradient es simplemente la dirección del gradiente de una imagen.
Procedimiento del algoritmo HOG:
- Dada la imagen de un objeto particular, seleccionar una determinada región de interés que cubra al objeto entero.
- Calcula la magnitud y la dirección del gradiente para cada píxel individualmente en la región seleccionada.
- Divide la región de detección en células de píxeles conectadas con el mismo tamaño. El tamaño de las células se suele escoger para que coincida con el tamaño de los features del objeto.
- Crea un histograma para cada célula, primero agrupando las direcciones de gradiente de todos los píxeles en cada célula en un número de bins medidos por la orientación. Y después añadiendo las magnitudes de los gradientes de los gradientes de cada bin. El número de bins del histograma suele situarse a 9.
- Agrupar células adyacentes en bloques. La distancia entre cada bloque suele ser la mitad del bloque de forma que así obtenemos bloques unos encima de otros.
- Utilizar las células contenidas en cada bloque para normalizar el historial de las células de cada bloque.
- Colectar todos los histogramas normalizados de los diferentes bloques en un único feature vector denominado HOG descriptor.
- Utilizar el HOG descriptor resultante de muchas imágenes del mismo tipo del objeto para entrenar un algoritmo de ML como SVM (Support Vector Machines) para así detectar ese tipo de objetos en imágenes.
- Una vez entrenado el SVM, un enfoque de ventana deslizante es utilizado para tratar de detectar y localizar objetos en una imagen buscado los patrones de la imagen que son similares a los patrones HOG aprendiedos por el SVM.
Para ver el algoritmo implementado ver el archivo “Histogram of Oriented Gradients”.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}