Teoría

Escrito por
5 minutos de lectura
Arquitecturas de CNN avanzadas
Localización
Este término hace referencia a dónde está localizado el objeto en la imagen.
Una forma de llevar a cabo la localización es, una vez creado el feature vector de nuestra CNN, utilizar una fully connected layer para predecir las class scores y hacer la predicción y otra fully connected layer del mismo feature vector para predecir la localización y el tamaño de la bounding box.
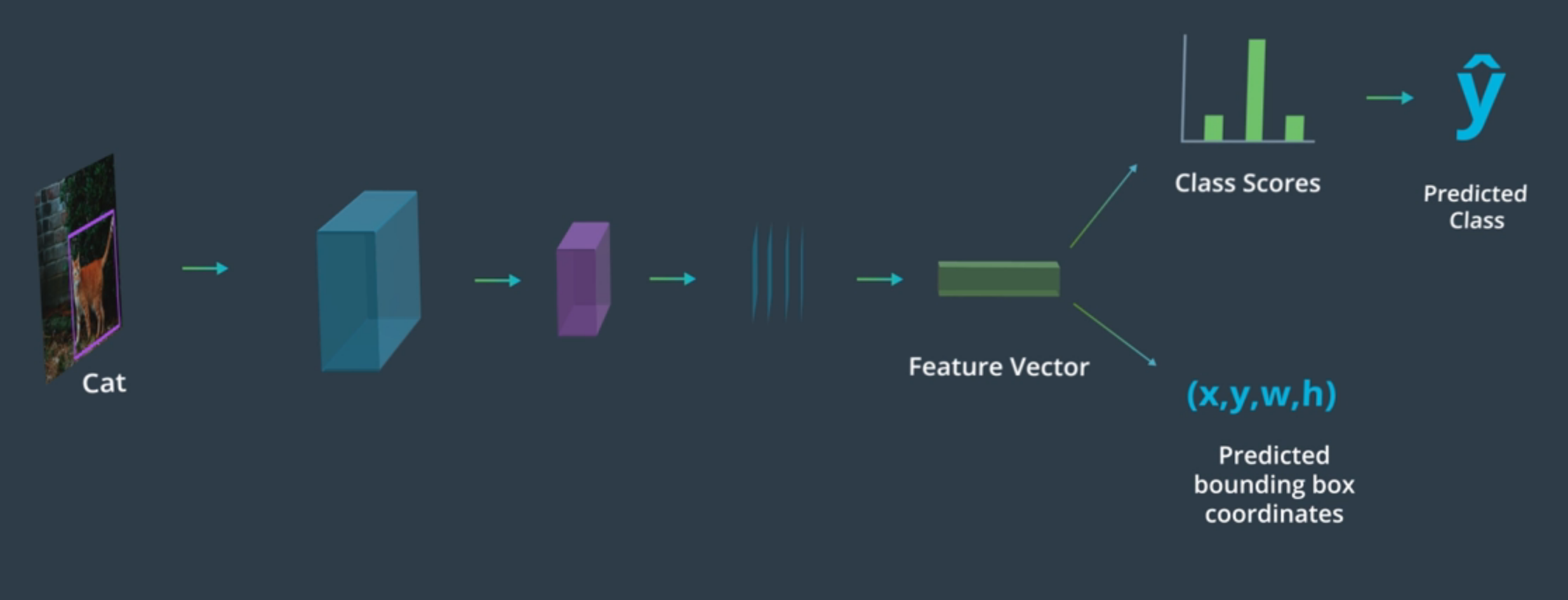
CNN con clasificación y localización - Imagen de Udacity
Bounding boxes y regresión
Cuando comparamos un set de puntos (por ejemplo puntos en una cara), estamos ante un problema de regresión y no de clasificación.
La clasificación es utilizada para obtener la clase, la regresión para obtener la cantidad.
En estos problemas de regresión hablamos sobre modelos con poco error en vez de modelos precisos.
Ejemplos de funciones de error:
-
L1 Loss: Calcula la resta entre cada elemento de el output predicho (P) y el real o target (T).
Puede resultar insignificante para valores con un pequeño error.
-
MSE Loss: Calcula el error cuadrático medio entre la el output predicho y el real.
Acaba amplificando errores que son grandes pero poco frecuentes conocidos como outliers.
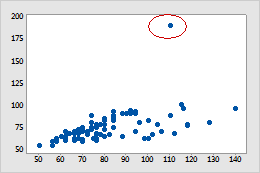
-
Smooth L1 Loss: Es una combinación de las anteriores, la cual trata de solventar sus problemas. Utiliza el error cuadrático medio para valores pequeños y el L1 Loss para valores mayores.
Un ejemplo un poco más avanzado que los bounding boxes pero que igualmente trata de localizar los valores de las coordenadas del output es el human post estimation.
Human Pose Estimation - Imagen de Catherine Dong
Uno de los problemas de la localización es que el número de outputs varía según el número de objetos de la imagen. Pero la CNN como la mayoría de redes neuronales tiene un único output. Por lo que para detectar una cantidad variable de objetos en una imagen, debemos descomponer la imagen en regiones más pequeñas.
De esta forma, podemos crear bounding boxes y asignar clases para cada región al mismo tiempo.
R-CNN
Para generar un buen set de regiones recortadas (regiones de interés), se introdujo la idea de region proposals. Estas nos dan las secciones de una imagen en las que puede haber un objeto. Para hacerlo podemos utilizar la detección de features como bordes o cambios en la textura.
A veces las region proposals nos pueden ocasionar que las regiones en las que no hayan objetos tengan mayor ruido, pero esto es un “coste a pagar” a cambio de incluir todos los objetos de la imagen.
Con el algoritmo de region proposals podemos hallar las regiones de interés (RoIs). Y tras esto las pasamos por una CNN de clasificación además de producir las coordenadas del bounding box para reducir errores de localización. A este modelo se le conoce con el nombre de Region Convolutional Neural Network (R-CNN).
Sin embargo, este proceso sigue requiriendo una gran cantidad de tiempo porque requiere que cada región recortada sea pasada por una CNN antes de la predicción de la clase.
Fast R-CNN
En vez de procesar con una CNN de clasificación cada sección de interés, esta arquitectura realiza una única CNN de clasificación a toda la imagen sólo una vez.
Seguimos necesitando identificar regiones de interés, pero en vez de recortar la imagen original proyectamos estos region proposals en la capa de feature maps (el resultado de la CNN).
De esta forma, podemos pasar por la fully connected layer cada feature map uno a uno el cual nos dará una clase para región. Para ello realizamos el RoI pooling que nos permite que cada feature map que le suministramos a la siguiente capa sea de la misma altura.
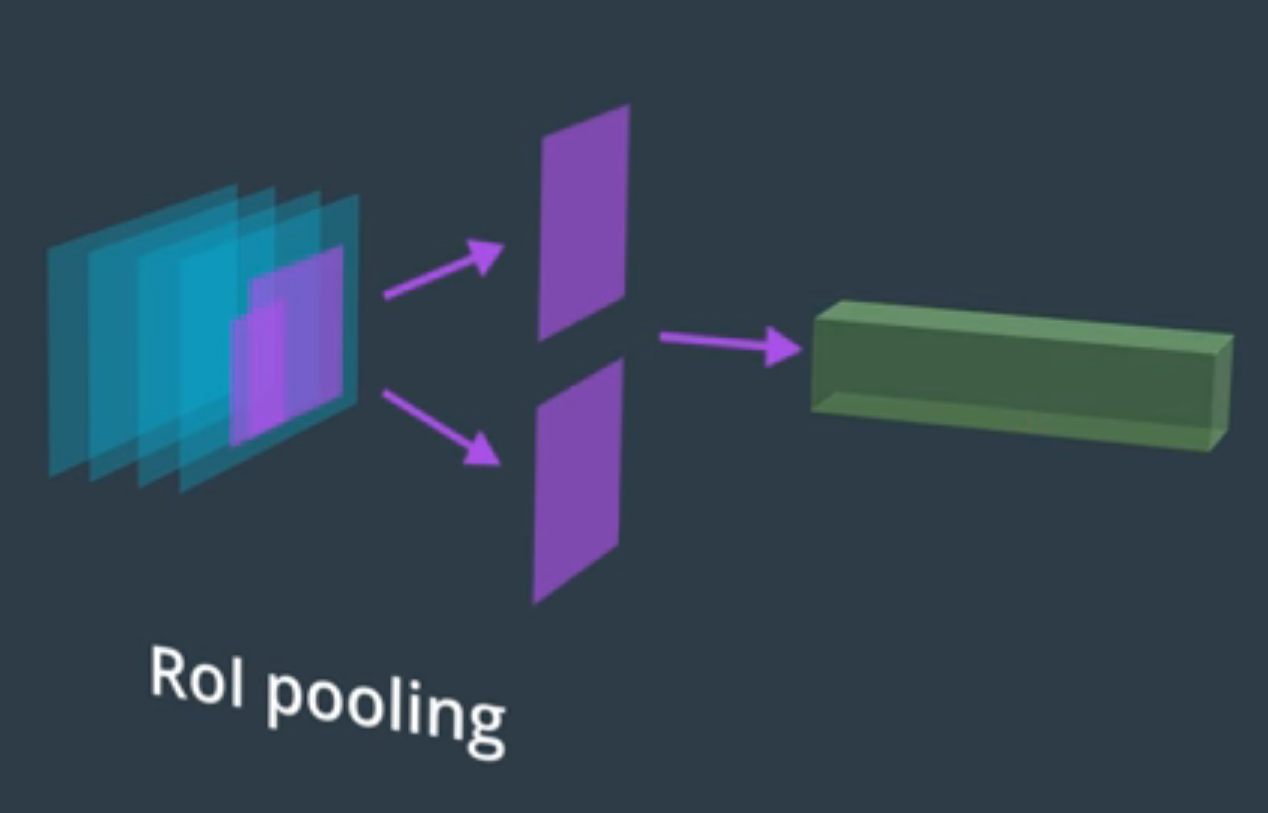
RoI pooling - Imagen de Udacity
Aún así esta región sigue siendo lenta al tener que general region proposals.
Recomiendo el siguiente enlace para un poco más de profundidad sobre las Fast R-CNN y el RoI pooling: Region of interest poolig explained
Faster R-CNN
Actúa igual que la Fast R-CNN pero utiliza los feature maps producidos como un input de una Region Proposals Network(RPN) separada. Así consigue obtener sus propias regiones de los features producidos en esta red. Si un área del feature map contiene gran cantidad de bordes detectados u otros features, es identificada como una región de interés.
Después de haber identificado la región de interés, realizada una rápida clasificación binaria. Por cada RoI se asegura se que una región tenga o no un objeto. Si la tiene, entonces la región continua continua en la red hasta la clasificación, sino el proposal es descartado.
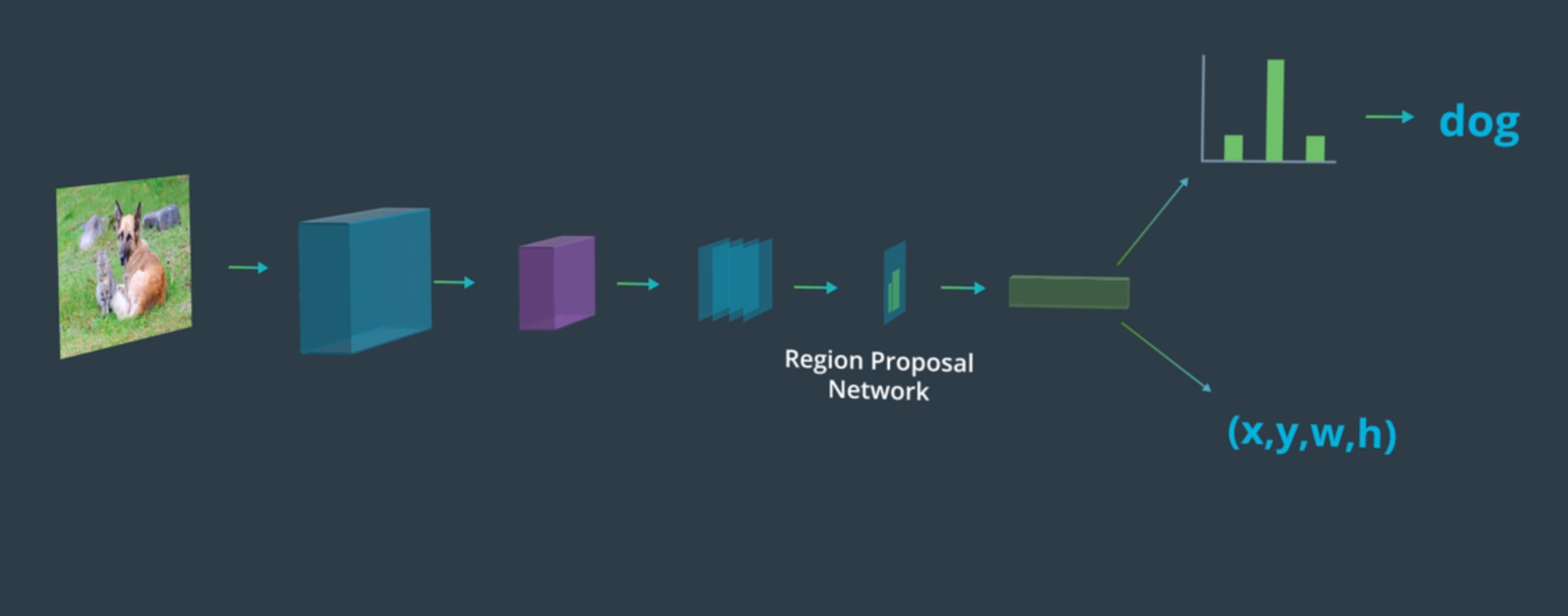
Faster R-CNN. Imagen de Udacity
Existen otros modelos que no utilizan modelos basados en los region proposals para detectar múltiples objetos (como YOLO o SSD) de los que hablaré en las siguientes secciones.
¿Quieres contactar conmigo?
Reporta un bug
Para cualquier error en la web o en la escritura, porfavor abre un issue en Github.
GithubMándame un mensaje
Siéntete libre de mandarme un tweet con cualquier recomendación o pregunta.
Twitter{kind=link}